Python. Cортировать в конце или держать отсортированным?
На днях я предложил подписчикам канала Oh My Py такую задачку:
Допустим, вы пишете программу, которой на вход последовательно, одно за другим, приходят числа. Ваша задача — накапливать их как-то, а потом, когда числа перестанут приходить — вернуть отсортированный список.
Как думаете, что будет работать быстрее:
- Складывать приходящие числа в неупорядоченную кучу, отсортировать в конце.
- Постоянно поддерживать отсортированный список (с помощью
bisect), в конце просто вернуть его.
Вот результаты голосования:
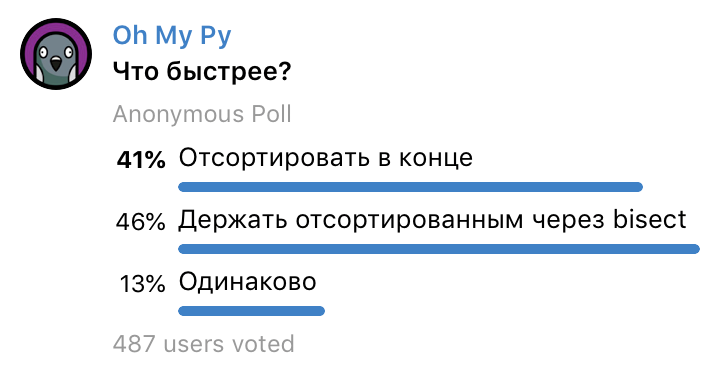
Давайте разберёмся, так ли это.
Решение
Сразу оговорюсь, что оценивать будем именно чистое время выполнения нашего обработчика. Понятно, что если источник будет присылать по одному числу в минуту, то общее время выполнения будет определяться именно скоростью источника, а не нашим обработчиком — вне зависимости от выбранного алгоритма. Поэтому исходим из того, что источник фигачит числами как из пулемёта.
Мы знаем, что сортировка на n числах занимает O(n logn) операций. Это сложность варианта «сортировать в конце».
Мы также знаем, что один бинарный поиск занимает O(log n) операций. В варианте «поддерживать отсортированным» мы выполняем поиск n раз, значит итоговая сложность O(n logn).
Там O(n logn) и тут O(n logn) — значит, варианты равнозначные, расходимся.
На самом деле нет ツ Посмотрите на реализацию варианта «поддерживать отсортированным»:
def keep_sorted(generator):
collection = []
for number in generator:
index = bisect.bisect(collection, number)
collection.insert(index, number)
return collection
Да, бинарный поиск выполняется за логарифмическое время. Но после него идёт вставка в массив — она занимает линейное время.
Таким образом, на каждое число алгоритм тратит O(n) операций, а на n чисел — O(n²). Это сильно медленнее, чем O(n logn).
Проверка
Чтобы не быть голословным, я реализовал оба варианта и сравнил их в действии.
Подготовка
Сначала подготовим генератор чисел:
import random
# будем генерить числа от 1 до 1 млн
RANGE_SIZE = 1 * 10**6
def number_generator(count):
for _ in range(count):
number = random.randint(1, RANGE_SIZE)
yield number
Затем реализуем алгоритм «сортировать в конце»:
from collections import deque
def sort_after(generator):
collection = deque()
for number in generator:
collection.append(number)
return sorted(collection)
И алгоритм «поддерживать отсортированным»:
import bisect
def keep_sorted(generator):
collection = []
for number in generator:
bisect.insort(collection, number)
return collection
Синхронная работа
Сначала рассмотрим вариант, когда генератор и обработчик работают строго последовательно: генератор присылает число, обработчик складывает его к себе, генератор присылает второе число, обработчик снова складывает, и так далее. Пока обработчик не закончил с числом, генератор не может прислать следующее.
Будем проверять на 1 млн чисел.
count = 1 * 10**6
Сортировать в конце:
%%time
sort_after(number_generator(count))
;
CPU times: user 1.33 s, sys: 20.1 ms, total: 1.35 s
Wall time: 1.35 s
Держать отсортированным:
%%time
keep_sorted(number_generator(count))
;
CPU times: user 1min 25s, sys: 74.9 ms, total: 1min 25s
Wall time: 1min 25s
Вариант «сортировать в конце» оказался быстрее в 63 раза (1.35 секунды против 85 секунд).
Асинхронная работа
Теперь пусть генератор и обработчик работают независимо. Генератор присылает числа с некоторым интервалом, а обработчик независимо складывает их к себе. Генератор не дожидается, пока обработчик закончит с очередным числом — он может прислать новое в любой момент.
Здесь придётся работать в два процесса (отдельно генератор, отдельно обработчик), так что будем использовать очередь для синхронизации. Генератор будет складывать в неё числа, а обработчик — забирать.
Кроме того, добавим генератору задержку:
import random
import time
def number_generator(queue, count, delay):
for _ in range(count):
number = random.randint(1, RANGE_SIZE)
queue.put(number)
time.sleep(delay)
queue.put(None)
Алгоритмы «сортировать в конце» и «поддерживать отсортированным» не слишком поменяются. Просто теперь они получают числа не из генератора, а из очереди:
from collections import deque
def sort_after(queue):
collection = deque()
while True:
number = queue.get()
if number is None:
break
collection.append(number)
return sorted(collection)
import bisect
def keep_sorted(queue):
collection = []
while True:
number = queue.get()
if number is None:
break
bisect.insort(collection, number)
return collection
Добавим вспомогательную функцию, которая создаёт процессы и запускает тест:
from multiprocessing import Process, Queue
def main(processor, count, delay):
print(f"count = {count}, delay = {delay}")
queue = Queue()
generator = Process(
target=number_generator,
args=(queue, count, delay),
daemon=True,
)
consumer = Process(target=processor, args=(queue,), daemon=True)
generator.start()
consumer.start()
generator.join()
consumer.join()
Будем проверять на 1 млн чисел и интервале между приходом чисел в 1 микросекунду:
count = 1 * 10**6
delay = 1 * 10**(-6)
%%time
main(sort_after, count, delay)
;
count = 1000000, delay = 1e-06
CPU times: user 3.12 ms, sys: 5.48 ms, total: 8.6 ms
Wall time: 29.3 s
%%time
main(keep_sorted, count, delay)
;
count = 1000000, delay = 1e-06
CPU times: user 3.81 ms, sys: 6.43 ms, total: 10.2 ms
Wall time: 1min 43s
Кажется, что разрыв сократился (29 секунд против 103). Но на самом деле эти 29 секунд уходят не на полезную работу, а на «обвязку» — возню вокруг time.sleep() и межпроцессное взаимодействие. Чтобы убедиться в этом, сделаем ещё один алгоритм, который вообще не сортирует приходящие числа, а просто возвращает их в финале как есть:
def do_not_sort(queue):
collection = deque()
while True:
number = queue.get()
if number is None:
break
collection.append(number)
return collection
%%time
main(do_not_sort, count, delay)
;
count = 1000000, delay = 1e-06
CPU times: user 2.93 ms, sys: 5.58 ms, total: 8.52 ms
Wall time: 29.1 s
Таким образом, «чистое» время работы «сортировать в конце» по-прежнему составляет около 1 секунды, а «держать отсортированным» — в десятки раз больше.
⌘ ⌘ ⌘
Итого: чистая победа «сортировать в конце» над «держать отсортированным» с большим отрывом.