SQL-шпаргалка
Это шпаргалка для студентов моих курсов по SQL и вообще всех, кто когда-то знал SQL, но подзабыл.
Мы будем использовать таблицу cities с городами России, население которых превышает 500 тыс. человек. Примеры интерактивные, так что можно заодно и потренироваться.
Основы
Базовые элементы, из которых строятся запросы.
select ... from ...
Выбирает строки из указанной таблицы. В каждой строке оставляет только перечисленные столбцы.
select city, population, timezone
from cities;
where
Оставляет в результате только те строки, которые подходят под условие.
select population, timezone
from cities
where city = 'Самара';
Условия бывают разные:
- строгое равенство:
city = 'Самара' - неравенство:
population > 10000 - вхождение в диапазон:
foundation_year between 1900 and 2000 - вхождение в перечисленный список:
region_type in ('край', 'обл') - совпадение с шаблоном:
postal_code like '105%' - проверка на пустое значение:
area is null
Условия можно комбинировать через or (выбрать строки, которые подходят под любое из условий):
select city, population
from cities
where city = 'Самара' or city = 'Новосибирск';
Или через and (выбрать строки, которые подходят одновременно под все условия):
select city, population
from cities
where federal_district = 'Сибирский' and region_type = 'край'
distinct
Выбирает только уникальные значения (то есть без повторов) перечисленных в select столбцов:
select distinct region_type
from cities;
order by
Сортирует результат по указанным столбцам.
select city, population
from cities
order by population;
По умолчанию сортирует от меньшего к большему, но если добавить desc — то наоборот:
select city, population
from cities
order by population desc;
limit
Оставляет только первые N строк результата. Обычно используется в связке с order by
select city, population
from cities
order by population
limit 5;
Группировка
Объединяем данные в группы и считаем сводные показатели.
group by
Объединяет строки с одинаковым значением указанных столбцов. Используется в связке с одной из агрегатных функций:
count(*) — количество строк с одинаковым значением столбца из group by
-- количество городов в каждом федеральном округе
select federal_district, count(*)
from cities
group by federal_district;
sum(column) — сумма значений столбца column по строкам с одинаковым значением столбца из group by
-- общее население каждого федерального округа
select federal_district, sum(population)
from cities
group by federal_district;
avg(column) — среднее значение столбца column по строкам с одинаковым значением столбца из group by
-- среднее население города в каждом федеральном округе
select federal_district, avg(population)
from cities
group by federal_district;
max(column) — максимальное значение столбца column среди строк с одинаковым значением столбца из group by
-- самое большое население города в каждом федеральном округе
select federal_district, max(population)
from cities
group by federal_district;
min(column) — минимальное значение столбца column среди строк с одинаковым значением столбца из group by
-- самое маленькое население города в каждом федеральном округе
select federal_district, min(population)
from cities
group by federal_district;
having
Отсеивает строки из результата уже после того, как отработал group by. Этим отличается от where, который отсеивает до того, как отработал group by.
-- федеральные округа, в которых больше 5 городов
select federal_district, count(*)
from cities
group by federal_district
having count(*) > 5;
Соединение таблиц
Соединение нескольких таблиц в результате запроса.
Допустим, есть две таблицы — вакансии (vacancy) и работодатели (employer):
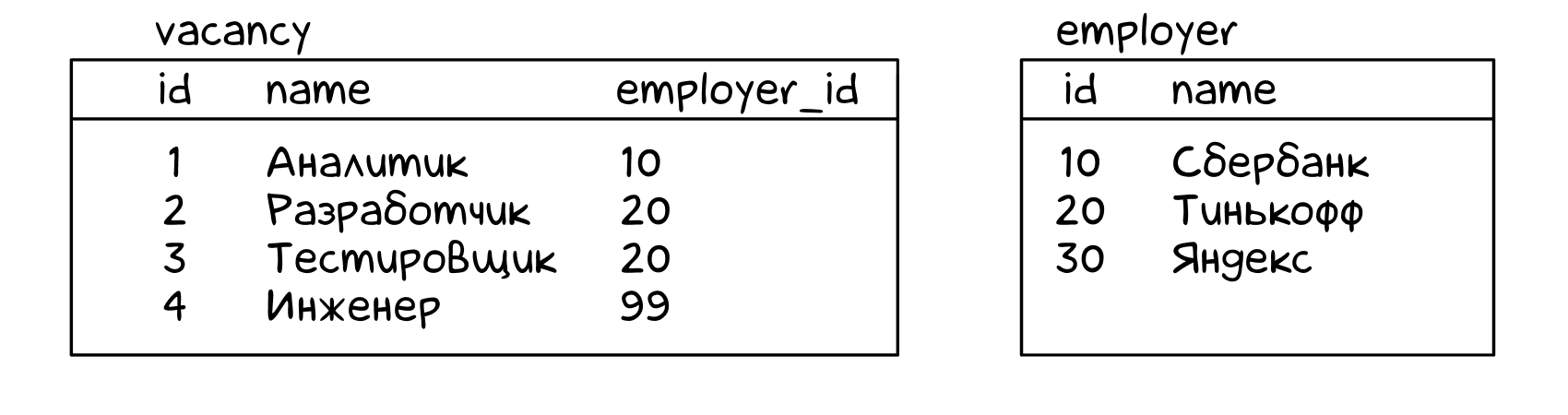
В таблице вакансий есть идентификатор работодателя — employer_id. А вот названия работодателя нет, оно в таблице employer.
Внутренний JOIN (он же INNER JOIN)
Мы хотим выбрать записи из vacancy, но добавить к ним название работодателя (employer.name). В этом поможет операция соединения таблиц — join:
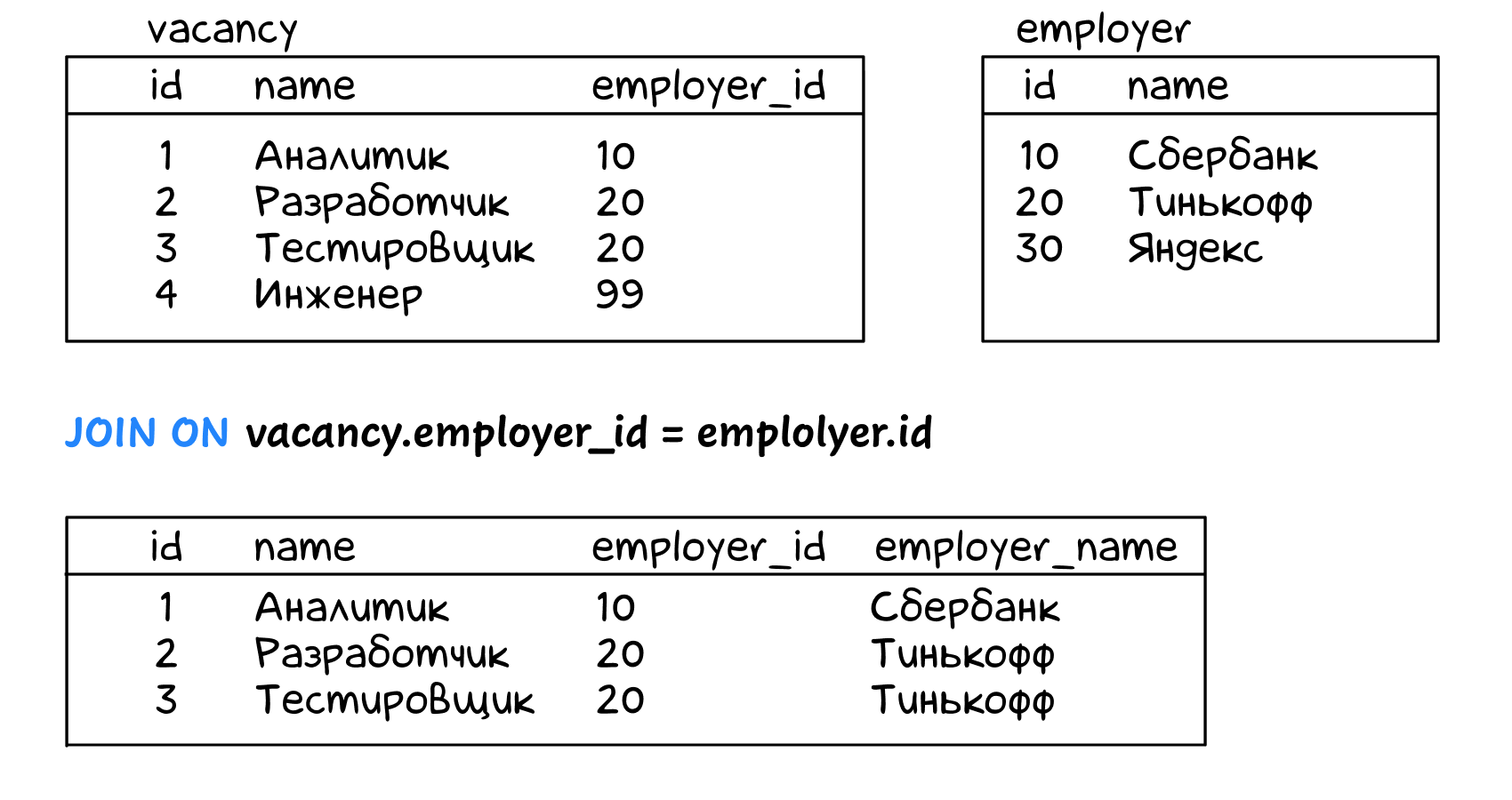
select
vacancy.id,
vacancy.name,
vacancy.employer_id,
employer.name as employer_name
from vacancy
join employer on vacancy.employer_id = employer.id;
Для каждой строчки vacancy движок базы данных лезет в таблицу employer, находит там значение id = vacancy.employer_id, извлекает name и добавляет в результат.
Если подходящее значение в employer не найдено (как для «инженера» в vacancy) — строчка не попадает в результат.
Внешний левый JOIN (LEFT JOIN)
Внешнее левое соединение очень похоже на обычное:
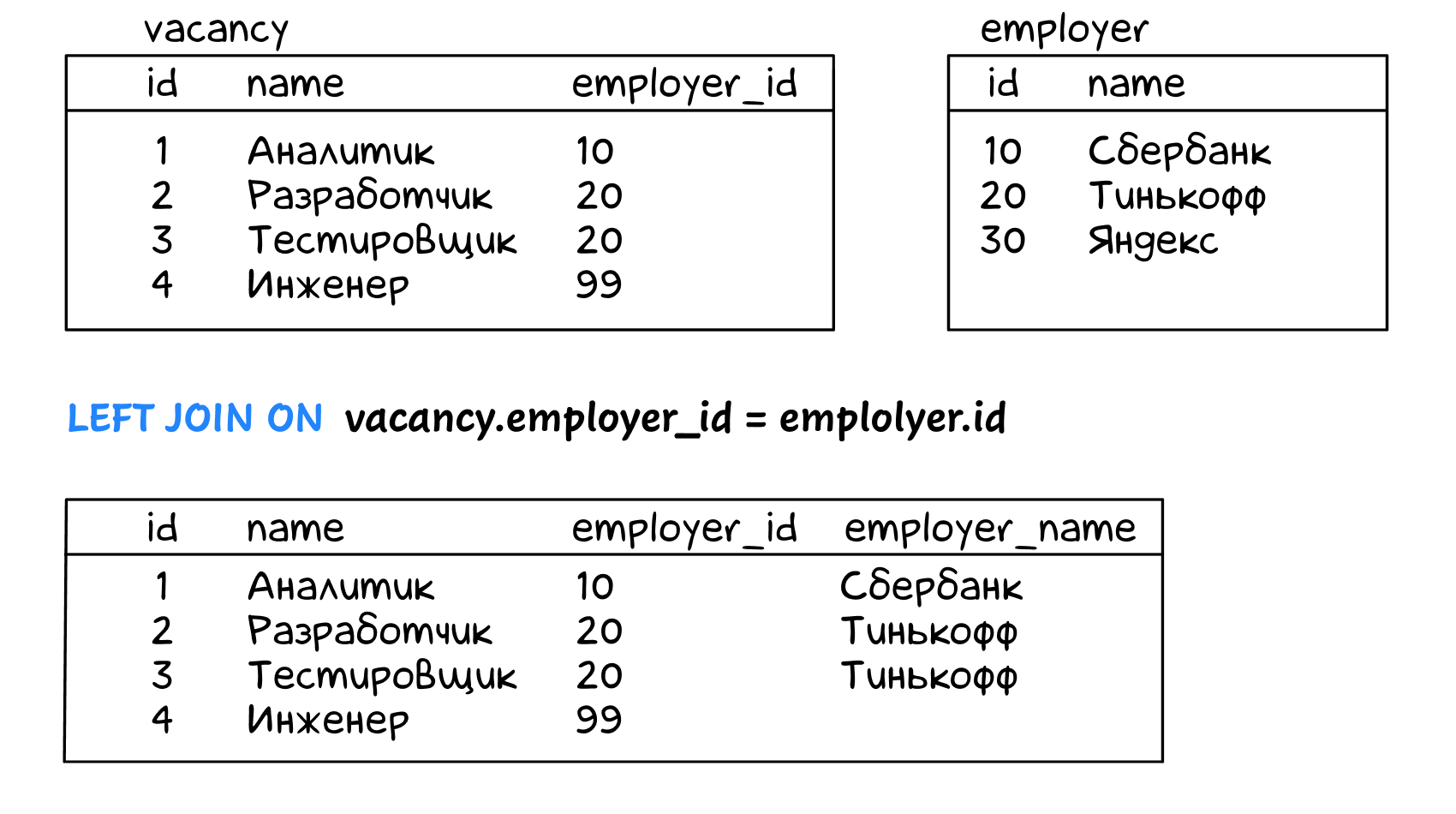
select
vacancy.id,
vacancy.name,
vacancy.employer_id,
employer.name as employer_name
from vacancy
left join employer on vacancy.employer_id = employer.id;
Разница только в том, что даже когда в employer не найдена строчка с id = vacancy.employer_id («инженер» в нашем примере) — строчка из vacancy все равно попадает в результат. Название работодателя при этом будет null.
Внутренний JOIN как бы говорит:
Дай записи из двух таблиц, у которых есть совпадение по указанному критерию.
Внешний левый JOIN же говорит:
Дай записи из двух таблиц, у которых есть совпадение по указанному критерию. И добавь к ним все записи из левой таблицы, для которых нет совпадения в правой.
Внешние соединения бывают не только левые, но еще правые (right join) и полные (full join). Детали в статье о JOIN.
Итого
Мы рассмотрели самые-самые основы SQL для выборки данных («селекты»):
- разделы запроса: столбцы, таблицы, фильтрация, сортировка;
- группировка данных и функции агрегации;
- соединение таблиц.
Конечно, у SQL намного больше возможностей, но это уже совсем другая история.
P.S. Хотите освоить современный SQL? Обратите внимание на Оконные функции