Виды JOIN в SQL
В SQL-джойнах скрыто больше, чем можно подумать. Давайте разберем их.
Будем использовать две простые таблицы: компании companies и их вакансии jobs.
Есть три вымышленные компании — Hoogle, Emazon и Neta — которые предлагают на удивление мало вакансий:
jobs companies
┌────────┬─────────┬──────────────┐ ┌─────────┬───────────┐
│ job_id │ comp_id │ job_name │ │ comp_id │ comp_name │
├────────┼─────────┼──────────────┤ ├─────────┼───────────┤
│ 1 │ 10 │ Data Analyst │ │ 10 │ Hoogle │
│ 2 │ 20 │ Go Developer │ │ 20 │ Emazon │
│ 3 │ 20 │ ML Engineer │ │ 30 │ Neta │
│ 4 │ 99 │ UI Designer │ └─────────┴───────────┘
└────────┴─────────┴──────────────┘
(свайпайте влево, чтобы увидеть компании)
Hoogle интересуется аналитиками данных. Emazon нанимает Go-разработчиков и ML-инженеров. У Neta нет вакансий. А какая-то ноунейм-компания с идентификатором 99 отчаянно разыскивает UI-дизайнера.
Время джойнить!
Квалифицированный JOIN
Квалифицированный джойн (qualified join) — это общий термин, которым обозначают всем известные типы джойнов: inner, left, right и full. Если вы про них не слышали или подзабыли — посмотрите SQL-шпаргалку.
Квалифицированный джойн соединяет два набора данных в один по заданным правилам. Вот как он выглядит в общем случае:
table [join-type] JOIN table join-specification
Таблица (table) — не обязательно прямо вот таблица. Это может быть представление, подзапрос или любая табличная структура данных. Но для краткости будем называть ее таблицей.
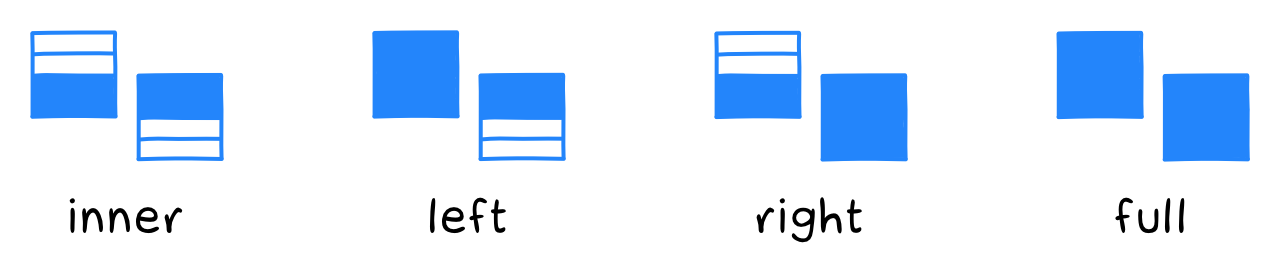
Тип джойна (join-type) может быть таким:
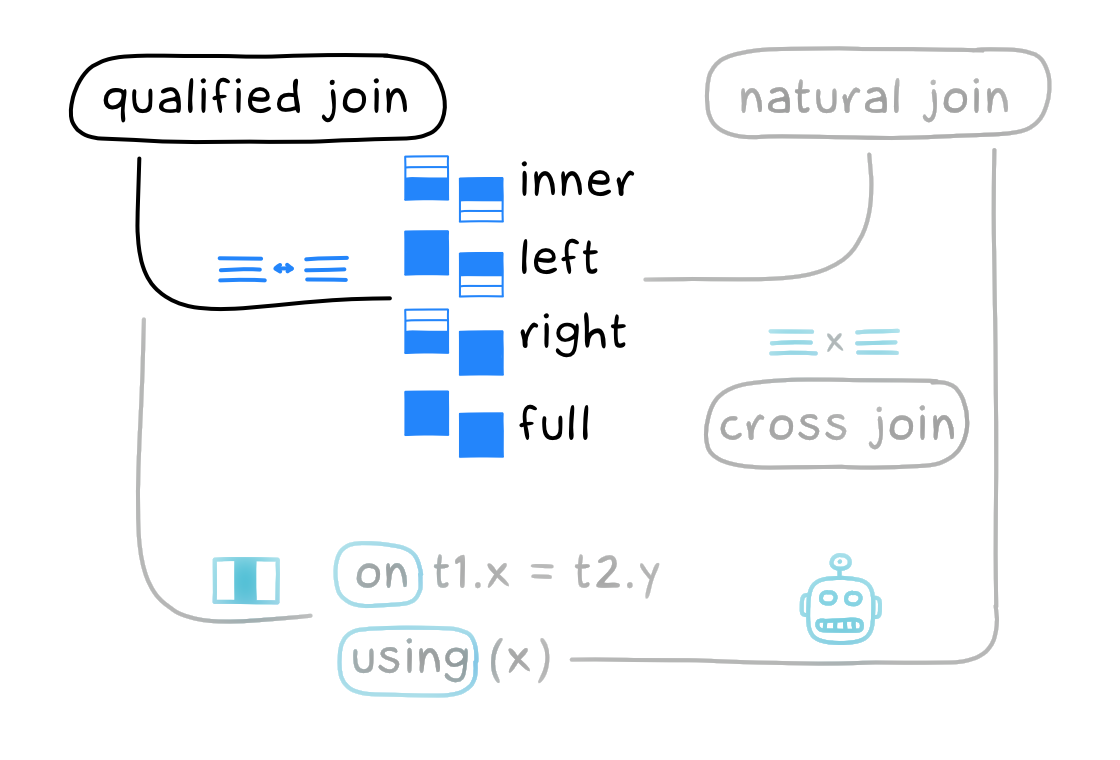
innerвключает только совпадающие записи из обеих таблиц.leftвключает совпадающие записи из обеих таблиц и несовпадающие из левой таблицы.rightвключает совпадающие записи из обеих таблиц и несовпадающие из правой таблицы.fullвключает совпадающие и несовпадающие записи из обеих таблиц.
Для left, right и full можно использовать необязательное слово outer, которое ничего не меняет (как будто SQL недостаточно сложный):
LEFT OUTER = LEFT
RIGHT OUTER = RIGHT
FULL OUTER = FULL
Да и вообще join-type можно не писать. По умолчанию джойн считается внутренним (inner).
Спецификация джойна (join-specification) задает правила соответствия между таблицами. Она бывает двух сортов.
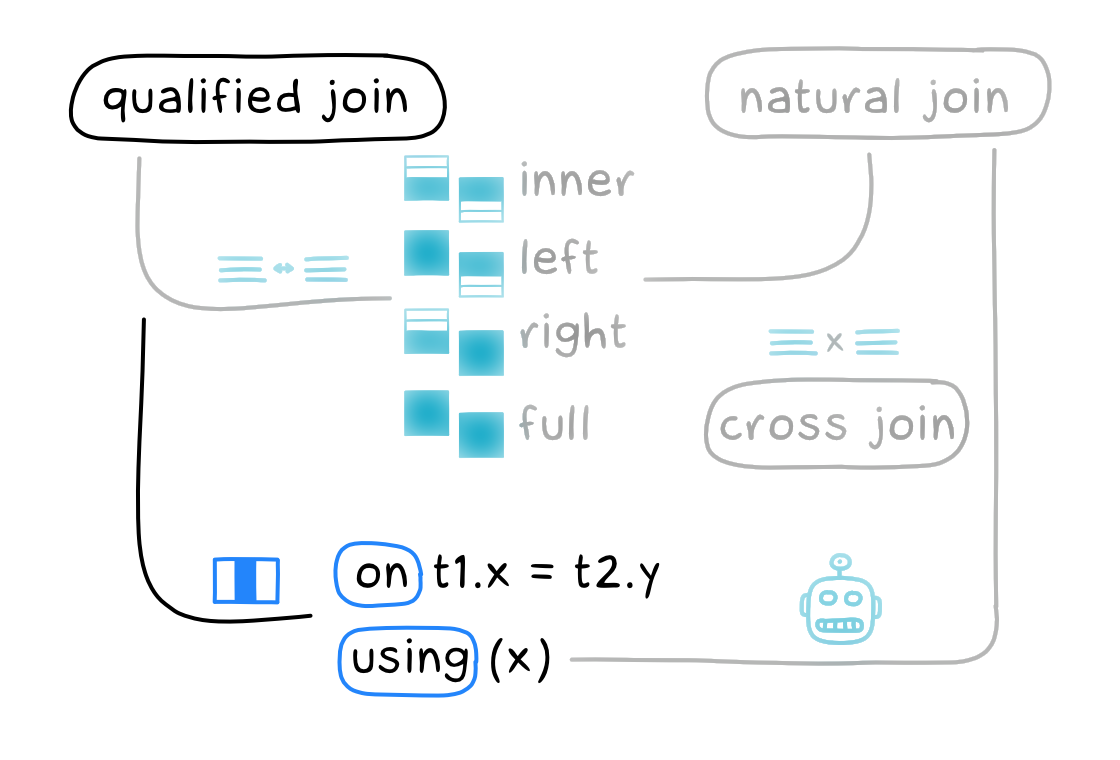
Первый вариант использует ключевое слово on, которое вы наверняка не раз встречали. Например, выберем вакансии вместе с соответствующими названиями компаний:
select
job_name, comp_name
from jobs
join companies on jobs.comp_id = companies.comp_id;
Второй вариант более редкий. Он использует ключевое слово using и работает, только если целевой столбец в обеих таблицах называется одинаково:
select
job_name, comp_name
from jobs
join companies using(comp_id);
С on можно использовать любые условия, а using проверяет только на равенство.
Удобно!
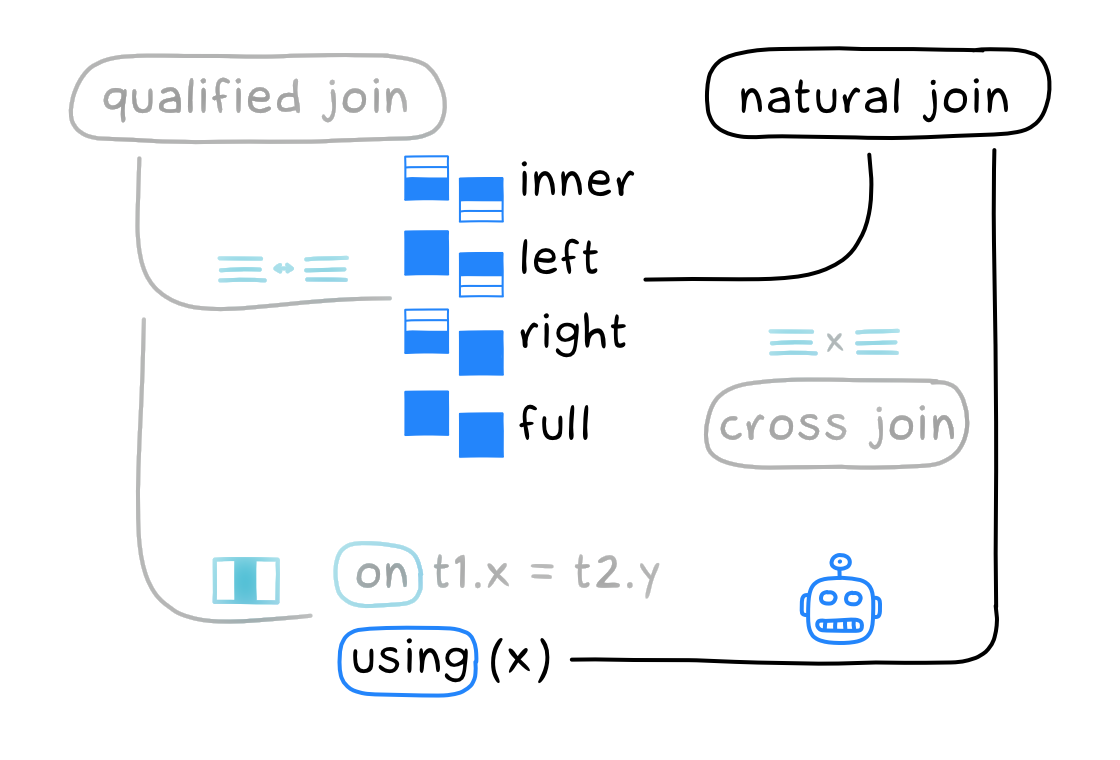
Естественный JOIN
Естественный джойн (natural join) — это как квалифицированный через using, только мы вообще не указываем столбцы, по которым соединяются таблицы:
select
job_name, comp_name
from jobs
natural join companies;
Естественный джойн находит все пары столбцов с одинаковыми названиями и использует их для соединения.
Аналогично using, естественный джойн проверяет на равенство. Аналогично квалифицированному джойну, он может быть внутренним (inner, по умолчанию) или внешним (left, right или full):
table NATURAL [join-type] JOIN table
Использовать естественный джойн — сомнительная идея. Допустим, у нас есть столбец name в обеих таблицах:
create table jobs (
job_id integer primary key,
comp_id integer,
name text
);
create table if not exists companies (
comp_id integer primary key,
name text
);
Вполне нормальная структура. Но естественный джойн между jobs и companies вернет пустой результат, потому что неявно сравнивает по такому условию:
jobs.comp_id = companies.comp_id and jobs.name = companies.name
Так что лично я без раздумий выбираю using вместо естественного соединения.
Перекрестный JOIN
Третья и последняя разновидность — перекрестный джойн (cross join), также известный как «декартово соединение» (Cartesian join):
select
job_name, comp_name
from jobs
cross join companies;
Перекрестный джойн игнорирует значения столбцов. Он берет каждую строку из левой таблицы (N строк) и соединяет с каждой строкой из правой таблицы (M строк), выдавая в результате N×M строк.
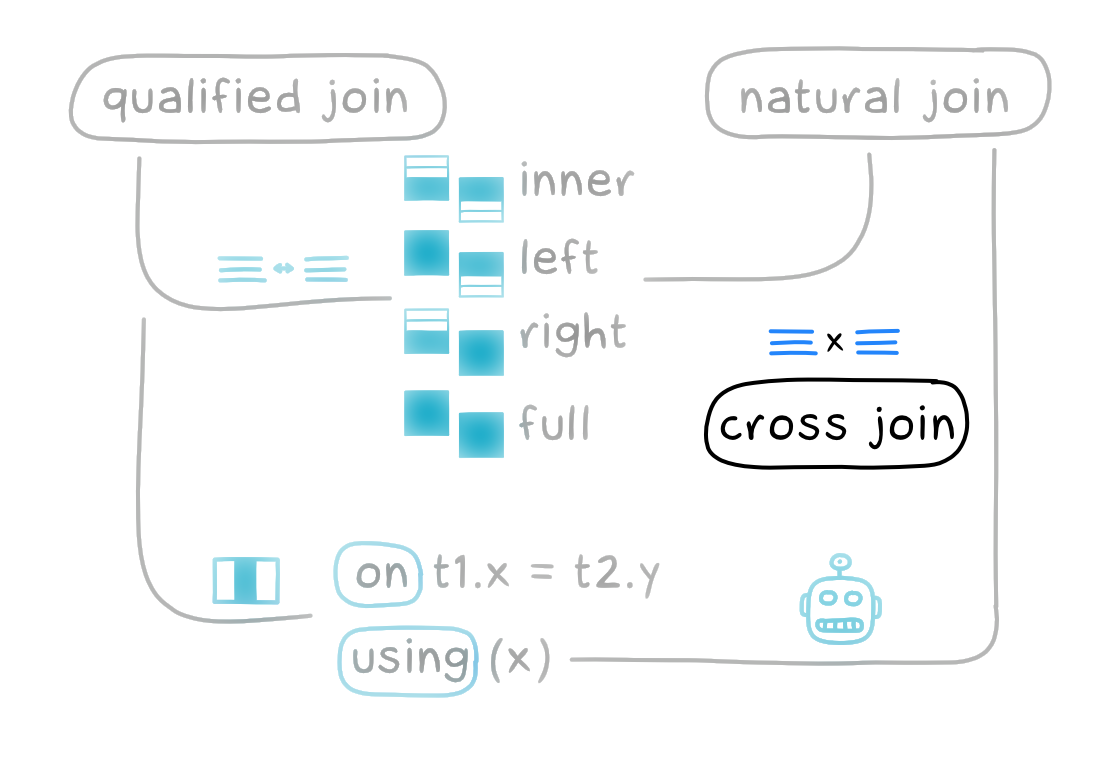
Перекрестный джойн полезен, чтобы получить все пары значений из двух таблиц. Например, комбинации «цвет-размер» по всем продуктам. В нашем примере с вакансиями толку от него немного.
Перекрестный джойн — то же самое, что внутренний джойн (inner join, он же просто join) без критерия совпадения:
select
job_name, comp_name
from jobs
join companies on true;
Иногда перекрестный джойн записывают так:
select job_name, comp_name
from jobs, companies;
Хотя в запрос вообще отсутствует слово join, это все то же самое перекрестное соединение.
Секционированный JOIN
Не я ли чуть выше говорил, что существует всего три вида джойнов — квалифицированный, естественный и перекрестный? Ну да.
Но тут вот какая штука. Помните определение квалифицированного джойна?
table [join-type] JOIN table join-specification
Согласно стандарту SQL, вместо table здесь можно использовать секционированную джойн-таблицу (partitioned join table):
select ...
from table_x partition by (col_1, col_2, ...)
join table_y on ...
;
Допустим у нас есть таблица продуктов (products) и продаж (sales) по дням:
sales products
┌────┬────────────┬────────────┬──────────┐ ┌────┬───────┐
│ id │ sale_dt │ product_id │ quantity │ │ id │ name │
├────┼────────────┼────────────┼──────────┤ ├────┼───────┤
│ 1 │ 2023-06-01 │ 10 │ 30 │ │ 10 │ Alpha │
│ 2 │ 2023-06-01 │ 20 │ 60 │ │ 20 │ Beta │
│ 3 │ 2023-06-01 │ 30 │ 90 │ │ 30 │ Gamma │
│ 4 │ 2023-06-02 │ 20 │ 60 │ └────┴───────┘
│ 5 │ 2023-06-03 │ 10 │ 30 │
│ 6 │ 2023-06-03 │ 30 │ 90 │
└────┴────────────┴────────────┴──────────┘
(свайпайте влево, чтобы увидеть продукты)
Выберем продажи с соответствующими названиями продуктов:
select
sale_dt, products.name, quantity
from sales
join products on sales.product_id = products.id
order by sale_dt;
Пока все просто. Но что если я хочу увидеть продажи каждого продукта за каждый день? Включая дни, в которые не было продаж отдельных продуктов:
┌────────────┬───────┬──────────┐
│ sale_dt │ name │ quantity │
├────────────┼───────┼──────────┤
│ 2023-06-01 │ Alpha │ 30 │
│ 2023-06-01 │ Beta │ 60 │
│ 2023-06-01 │ Gamma │ 90 │
│ 2023-06-02 │ Alpha │ 0 │
│ 2023-06-02 │ Beta │ 60 │
│ 2023-06-02 │ Gamma │ 0 │
│ 2023-06-03 │ Alpha │ 30 │
│ 2023-06-03 │ Beta │ 0 │
│ 2023-06-03 │ Gamma │ 90 │
└────────────┴───────┴──────────┘
Эту задачу никак не решить без дополнительных ухищрений. Разве что использовать секционированный джойн (partitioned join).
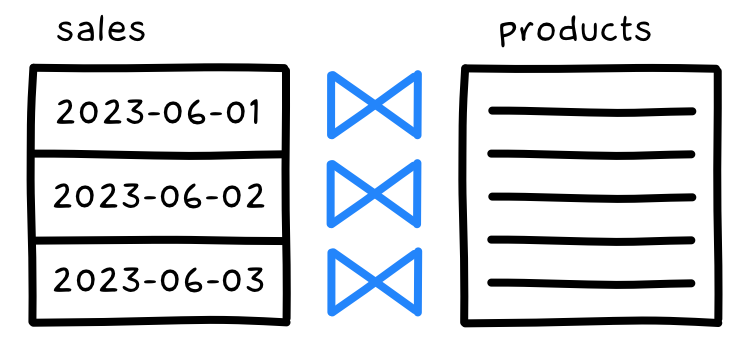
Секционированный джойн говорит движку СУБД выполнять соединение отдельно по каждой секции, которую мы задали для таблицы. Поэтому, если мы определим секции продаж по дате:
select
sale_dt, name, quantity
from sales partition by (sale_dt)
right join products on sales.product_id = products.id
order by sale_dt, name;
То движок независимо соединит продажи за 01.06 со всеми продуктами, затем продажи за 02.06 со всеми продуктами, затем продажи за 03.06 со всеми продуктами, и наконец объединит промежуточные результаты. В результате получим искомый набор данных (разве что вместо 0 здесь null):
┌────────────┬───────┬──────────┐
│ sale_dt │ name │ quantity │
├────────────┼───────┼──────────┤
│ 2023-06-01 │ Alpha │ 30 │
│ 2023-06-01 │ Beta │ 60 │
│ 2023-06-01 │ Gamma │ 90 │
│ 2023-06-02 │ Alpha │ (null) │
│ 2023-06-02 │ Beta │ 60 │
│ 2023-06-02 │ Gamma │ (null) │
│ 2023-06-03 │ Alpha │ 30 │
│ 2023-06-03 │ Beta │ (null) │
│ 2023-06-03 │ Gamma │ 90 │
└────────────┴───────┴──────────┘
Надо сказать, что странноватая фича. Я удивлен, что она вообще вошла в стандарт (подозрительно связано с тем, что она реализована в Oracle). Другие производители СУБД так никогда и не реализовали секционированный джойн. Не могу их за это осуждать.
В любом случае, теперь и вы знаете о существовании этого джойна. Не нести же мне бремя бесполезных SQL-знаний одному.
Если вам интересно, как решить задачу без секционированного джойна (знаю, что нет), то вот:
-- выбираем все даты
with dates as (
select distinct sale_dt
from sales
)
-- перекрестный джойн дат с продуктами
-- дает все пары «дата-продукт»,
-- а их уже соединяем с продажами
select
dates.sale_dt,
name, quantity
from dates
cross join products
left join sales on sales.sale_dt = dates.sale_dt
and sales.product_id = products.id
order by dates.sale_dt, name;
Проще простого.
Латеральный JOIN
SQL — странная штука. Стандарт одновременно включает и секционированный джойн (который никто кроме Oracle не поддержал), и намного более мощную и распространенную разновидность — латеральный (lateral) джойн.
Латеральное соединение, в противоположность обычному, разрешает коррелированные подзапросы. Сейчас разберемся, что это.
Вернемся к примеру с продуктами и продажами:
sales products
┌────┬────────────┬────────────┬──────────┐ ┌────┬───────┐
│ id │ sale_dt │ product_id │ quantity │ │ id │ name │
├────┼────────────┼────────────┼──────────┤ ├────┼───────┤
│ 1 │ 2023-06-01 │ 10 │ 30 │ │ 10 │ Alpha │
│ 2 │ 2023-06-01 │ 20 │ 60 │ │ 20 │ Beta │
│ 3 │ 2023-06-01 │ 30 │ 90 │ │ 30 │ Gamma │
│ 4 │ 2023-06-02 │ 20 │ 60 │ └────┴───────┘
│ 5 │ 2023-06-03 │ 10 │ 30 │
│ 6 │ 2023-06-03 │ 30 │ 90 │
└────┴────────────┴────────────┴──────────┘
(свайпайте влево, чтобы увидеть продукты)
Посмотрим, как каждый продукт продавался 2 июня:
select
'2023-06-02' as sale_dt, name, sales.quantity
from products
left join sales on products.id = sales.product_id
and sales.sale_dt = '2023-06-02';
А теперь посмотрим продажи каждого продукта за каждый день (как делали в примере с секционированным джойном). Было бы здорово выбрать даты отдельным подзапросом и соединить с подзапросом по конкретной дате из примера выше:
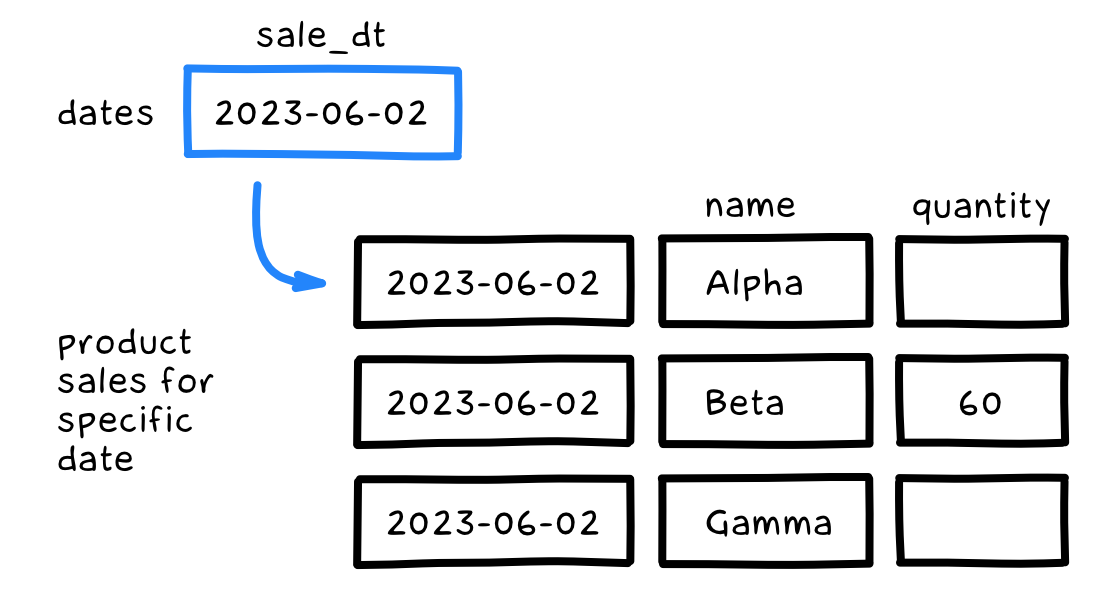
select
d.sale_dt, ps.name, ps.quantity
from
(select distinct sale_dt from sales) as d
join (
select d.sale_dt, name, sales.quantity
from products
left join sales on products.id = sales.product_id
and sales.sale_dt = d.sale_dt
) as ps on true
order by sale_dt, name;
Но нет. Нельзя использовать столбец sale_dt из подзапроса d в следующем за ним подзапросе ps. А вот если использовать латеральный джойн — можно:
select
d.sale_dt, ps.name, ps.quantity
from
(select distinct sale_dt from sales) as d
join lateral (
select d.sale_dt, name, sales.quantity
from products
left join sales on products.id = sales.product_id
and sales.sale_dt = d.sale_dt
) as ps on true
order by sale_dt, name;
Подзапрос d выбирает даты, а подзапрос ps соединяется с ним по столбцу sale_dt. Тем самым ps выбирает продажи каждого продукта для каждой конкретной даты. Все благодаря латеральному джойну. Удобно!
Может возникнут вопрос насчет условия on true. Дело в том, что фактически джойн по sale_dt уже произошел внутри подзапроса ps, поэтому повторять его снаружи не требуется. Можете поменять true на d.sale_dt = ps.sale_dt и убедиться, что ничего не изменилось.
Латеральные соединения поддерживаются в PostgreSQL, MySQL и Oracle. MS SQL Server не поддерживает синтаксис lateral, но предоставляет аналогичную функциональность с собственным синтаксисом cross apply (= join lateral) и outer apply (= left join lateral).
Итого
Стандарт SQL описывает три варианта JOIN:
- квалифицированный (соединение по указанным критериям);
- естественный (автоматически выбирает критерии);
- перекрестный (внутреннее соединение без критериев).
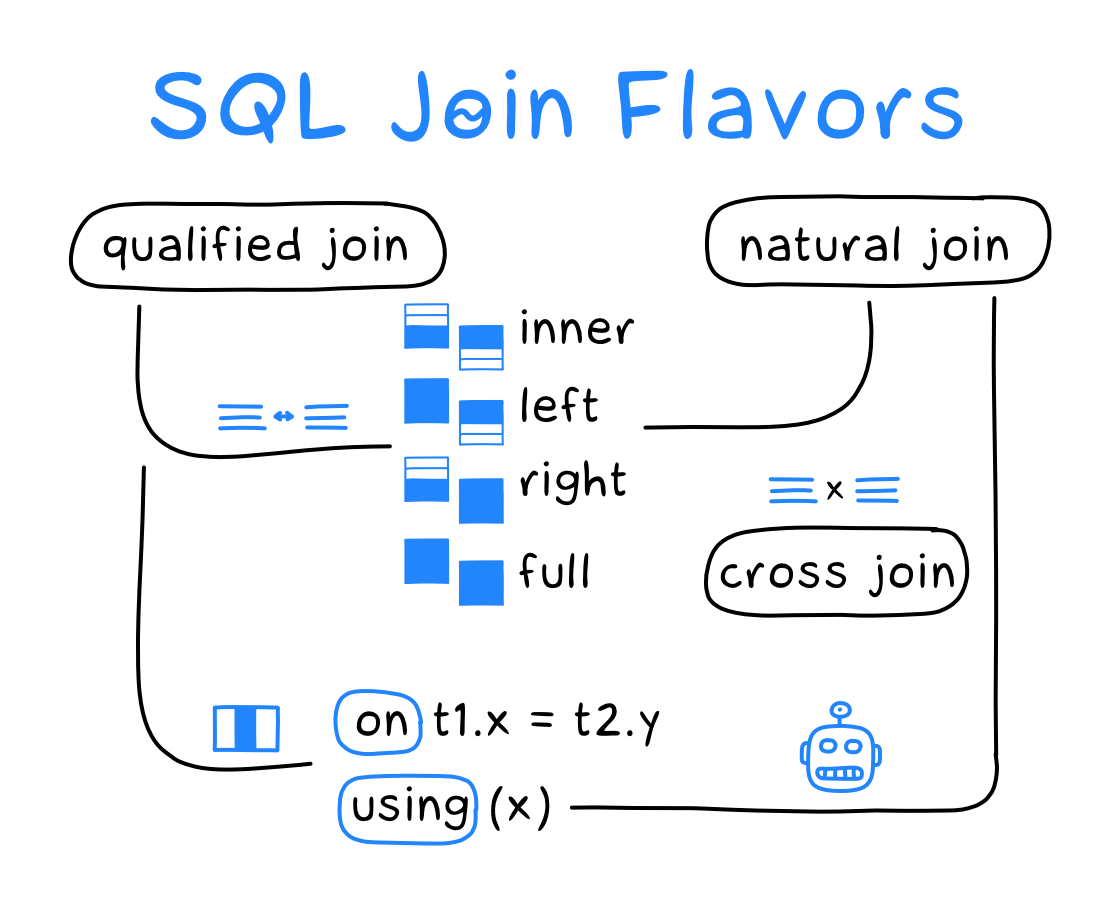
Квалифицированный джойн предусматривает четыре типа: inner, left, right и full.
Он разрешает задать критерии соединения через on или using.

Большинство производителей СУБД поддерживают все виды JOIN. Заметное исключение — MS SQL Server, который знать не знает о using и естественных джойнах.
Есть еще модификаторы, которые изменяют поведение джойна:
lateralразрешает коррелированные подзапросы вjoin-части запроса. Поддерживается в PostgreSQL, MySQL и Oracle (и MS SQL Server с другим синтаксисом).partition byпроизводит независимое соединение по каждой из заданных секций. Поддерживается только в Oracle.
И еще MySQL не поддерживает full-джойны. Просто чтобы жизнь сахаром не казалась.
Вот и все!
──
P.S. Хотите освоить современный SQL? Обратите внимание на Оконные функции