Оконные функции SQL: агрегация
Это фрагмент моего курса Оконные функции SQL с пошаговым изложением, наглядными иллюстрациями и практическими упражнениями.
На предыдущих уроках мы разобрали оконные функции ранжирования и смещения.
Агрегация — это когда мы считаем суммарные или средние показатели (агрегаты). Например, среднюю зарплату по каждому региону или количество золотых медалей у каждой страны в зачете Олимпийских игр.
Мы будем агрегировать данные по сотрудникам из таблицы employees:
┌────┬──────────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼──────────┼────────┼────────────┼────────┤
│ 11 │ Дарья │ Самара │ hr │ 70 │
│ 12 │ Борис │ Самара │ hr │ 78 │
│ 21 │ Елена │ Самара │ it │ 84 │
│ 22 │ Ксения │ Москва │ it │ 90 │
│ 23 │ Леонид │ Самара │ it │ 104 │
│ 24 │ Марина │ Москва │ it │ 104 │
│ 25 │ Иван │ Москва │ it │ 120 │
│ 31 │ Вероника │ Москва │ sales │ 96 │
│ 32 │ Григорий │ Самара │ sales │ 96 │
│ 33 │ Анна │ Москва │ sales │ 100 │
└────┴──────────┴────────┴────────────┴────────┘
Содержание:
Агрегат по секции
У каждого департамента есть фонд оплаты труда — денежная сумма, которая ежемесячно уходит на выплату зарплат сотрудникам. Посмотрим, какой процент от этого фонда составляет зарплата каждого сотрудника:
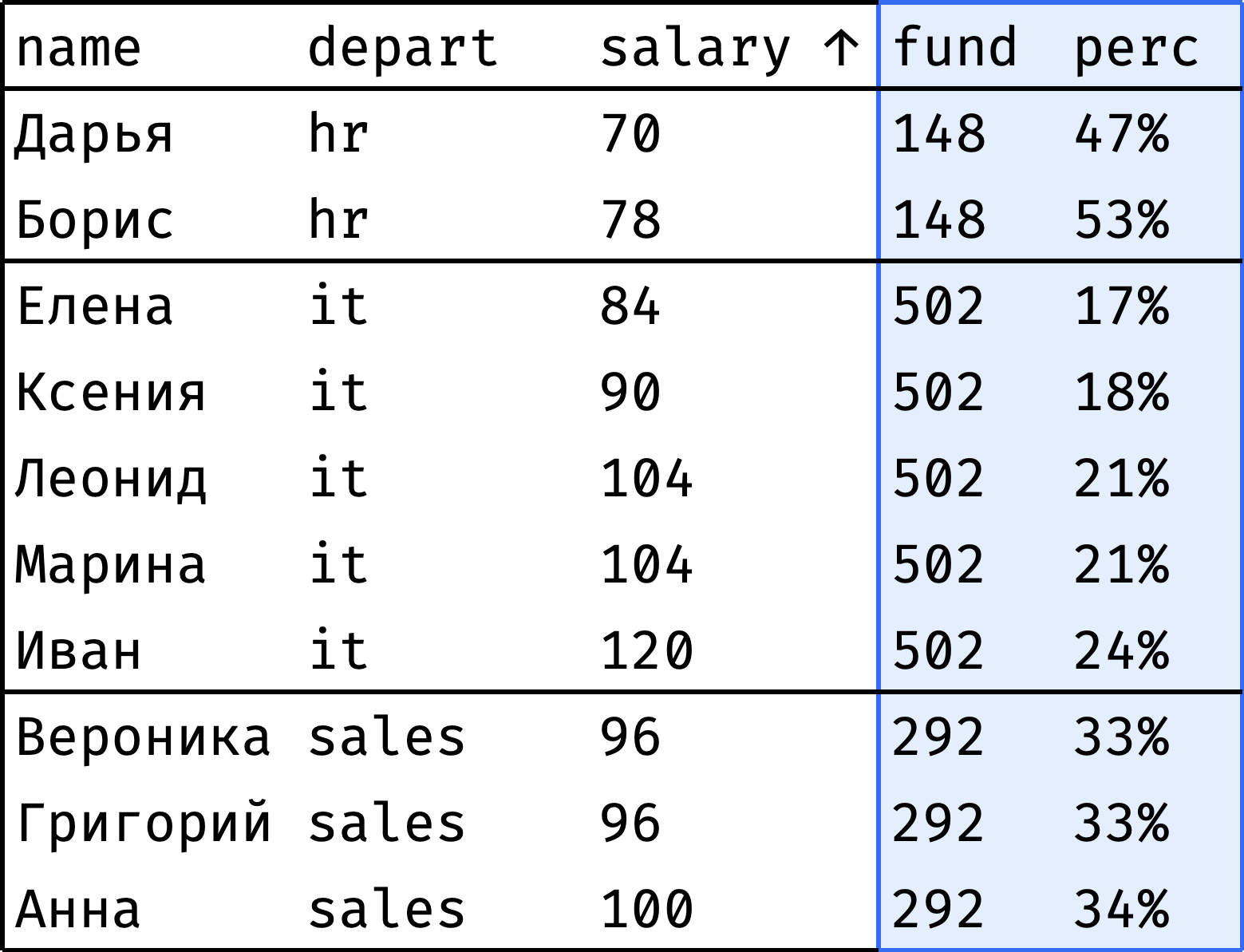
Столбец fund показывает фонд оплаты труда отдела, а perc — долю зарплаты сотрудника от этого фонда. Видно, что в HR и продажах все более-менее ровно, а у айтишников есть заметный разброс зарплат.
Как перейти от «было» к «стало»?
Отсортируем таблицу по департаментам:
select
name, department, salary,
null as fund, null as perc
from employees
order by department, salary, id;
Теперь пройдем от первой строчки до последней. На каждом шаге будем считать:
fund— сумму зарплат по департаменту в целом;perc— долю зарплаты сотрудника от этой суммы.
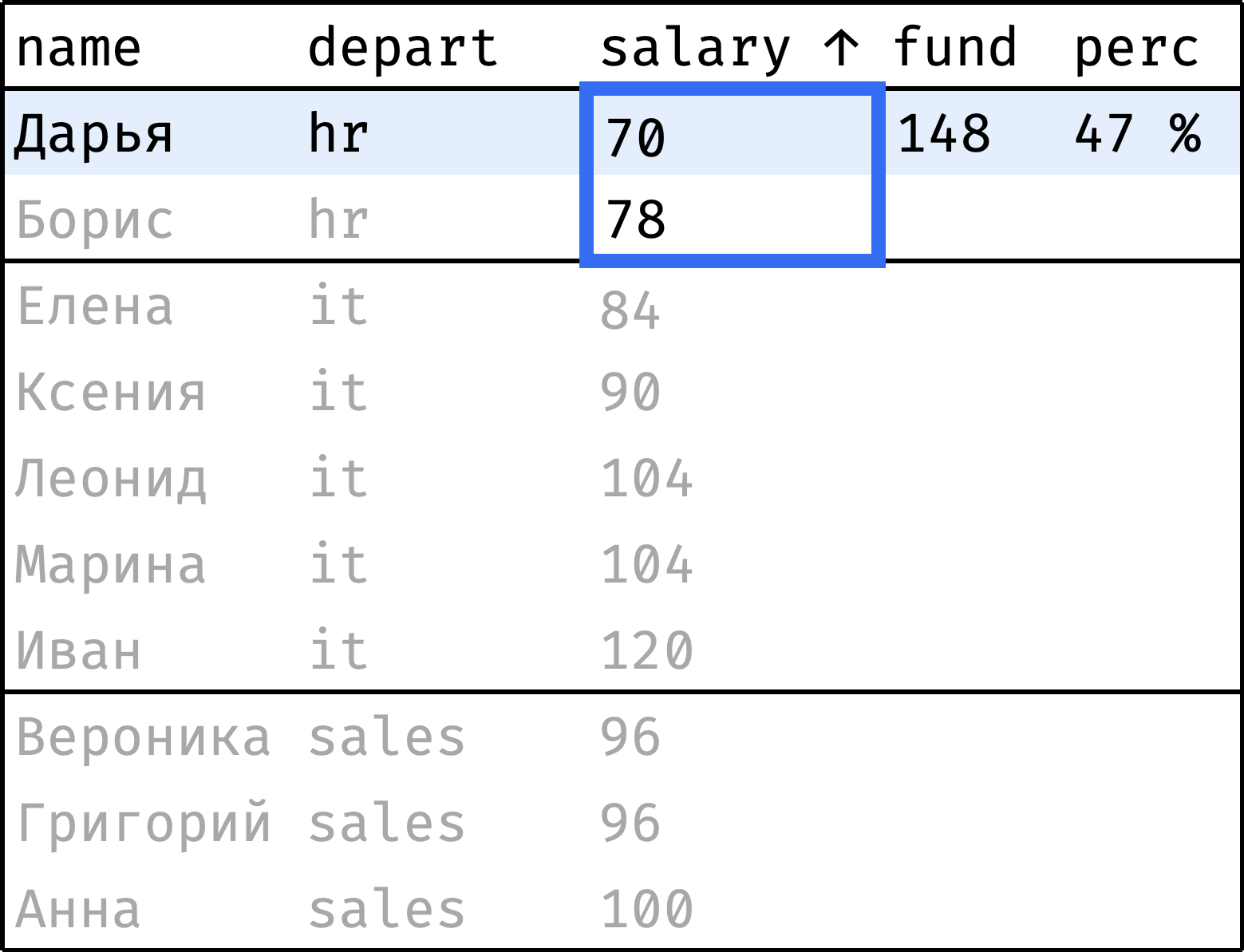
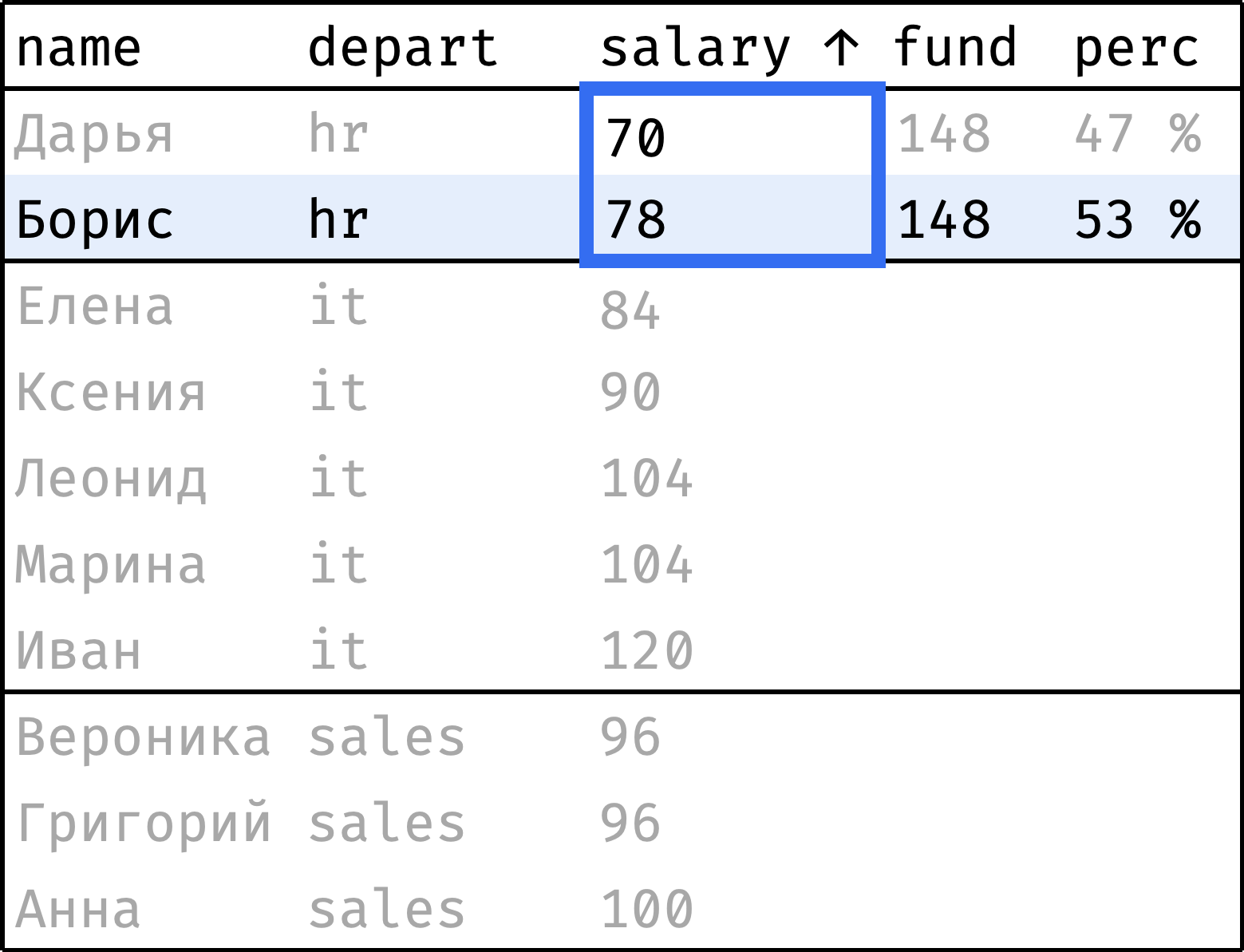
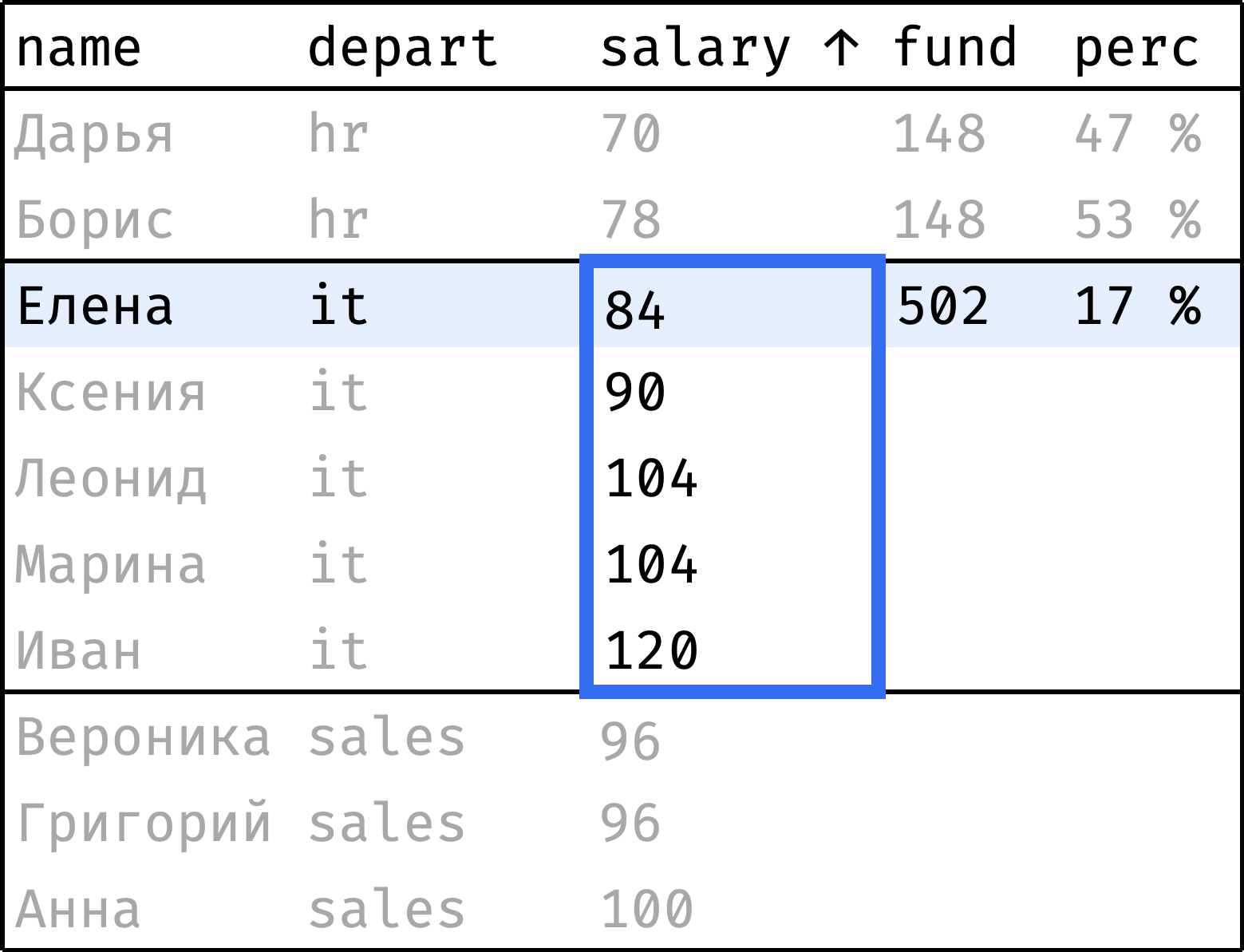
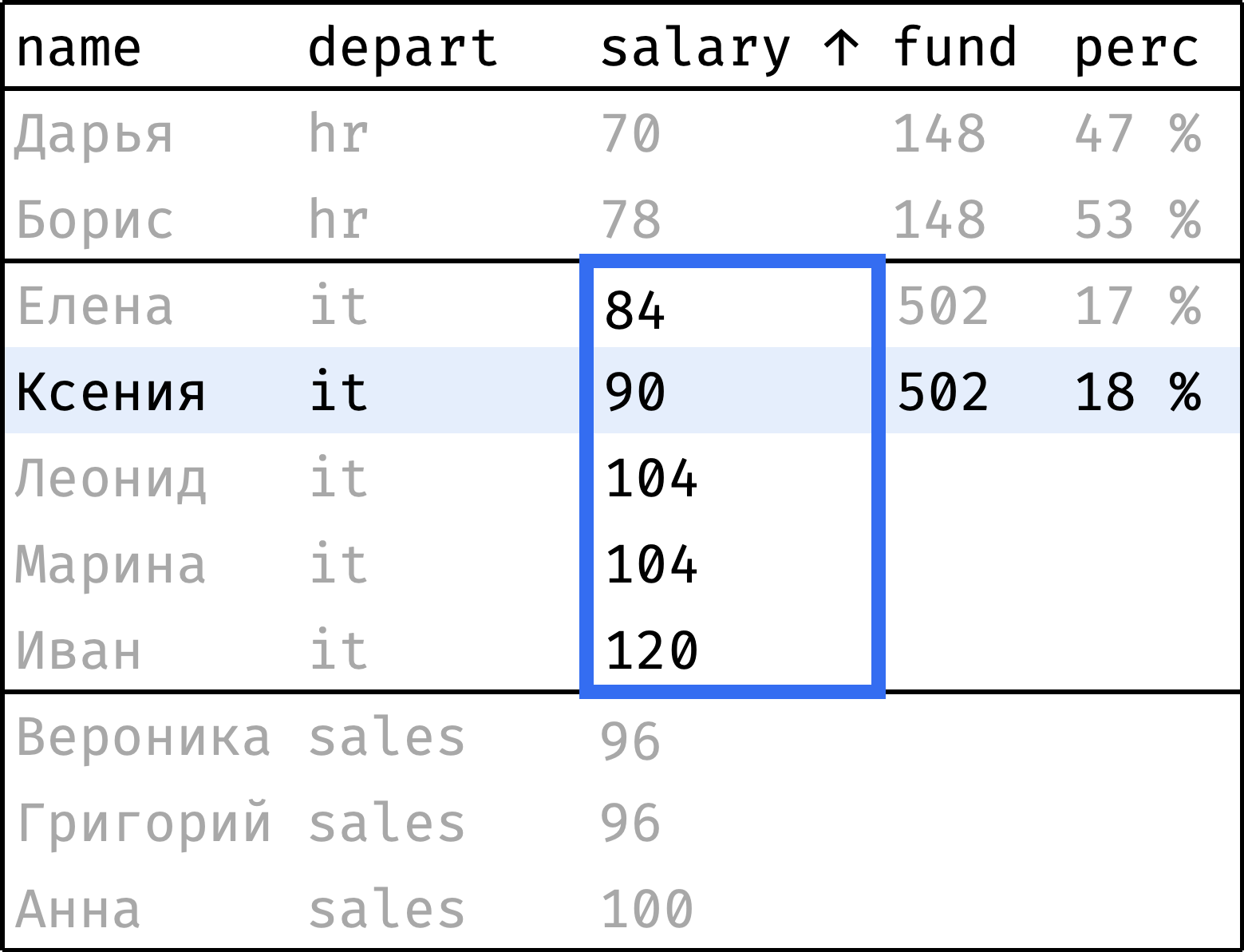
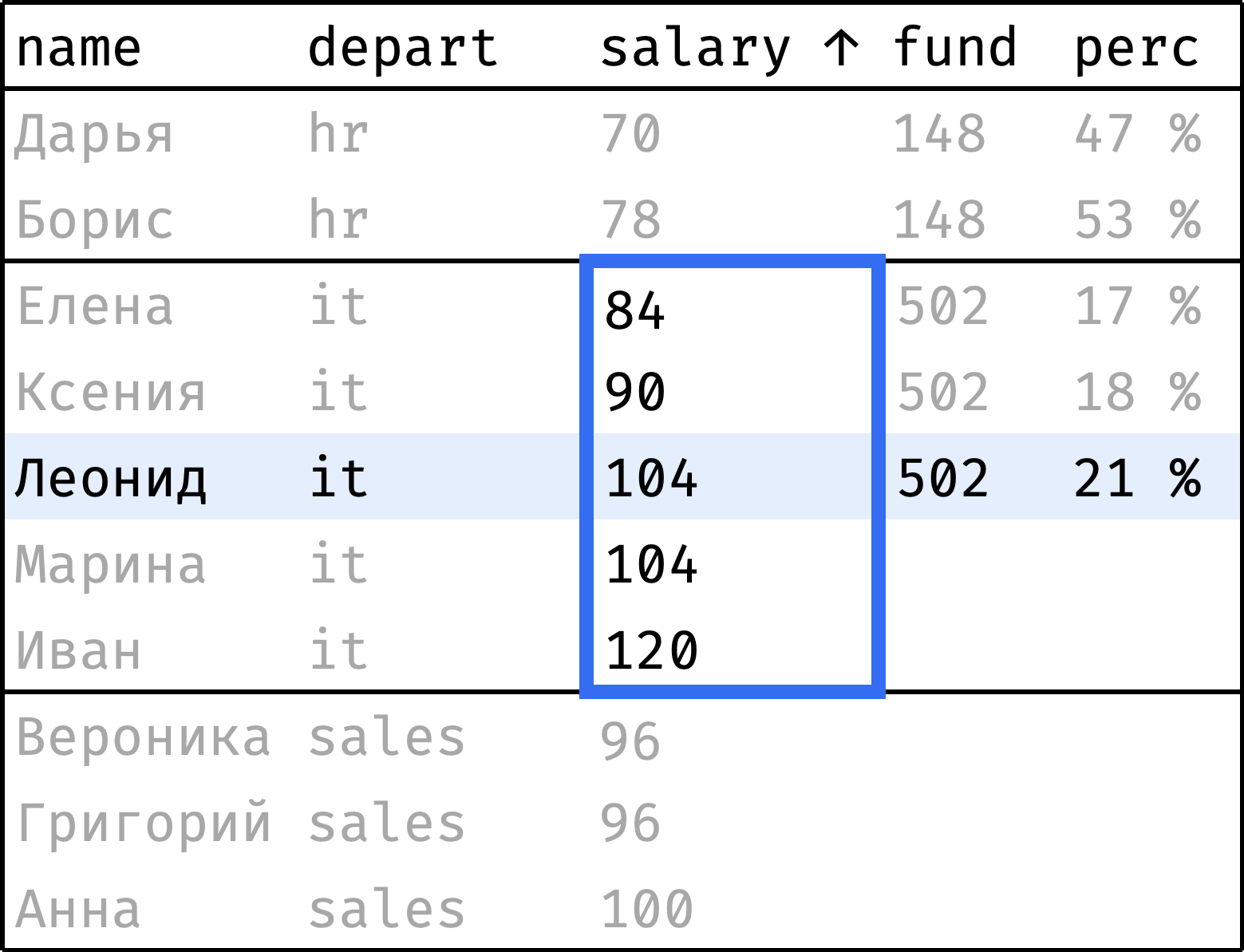
и так далее...
Одной гифкой:

Окно состоит из секций по департаментам. При этом порядок записей в секции неважен: мы считаем сумму значений salary, а она не зависит от порядка.
window w as (
partition by department
)
Для расчета fund подойдет обычная функция sum() — ее можно использовать поверх окна. А perc посчитаем как salary / fund:
select
name, department, salary,
sum(salary) over w as fund,
round(salary * 100.0 / sum(salary) over w) as perc
from employees
window w as (partition by department)
order by department, salary, id;
Функция sum() работает без неожиданностей — считает сумму значений по всей секции, которой принадлежит текущая строка.
✎ Задачка: Фонд оплаты труда по городу (+ еще одна)
Только практика превращает абстрактные знания в навыки. Поэтому я рекомендую не просто читать эту статью, а проходить курс или книгу — в них достаточно упражнений, чтобы уверенно освоить «окошки».
Если вас пока устраивает одна теория — продолжим.
Фильтрация и порядок выполнения
Вернемся к запросу, который считал фонд оплаты труда по департаменту:
select
name, department, salary,
sum(salary) over w as fund
from employees
window w as (partition by department)
order by department, salary, id;
Допустим, мы хотим оставить в отчете только самарских сотрудников. Добавим фильтр:
select
name, salary,
sum(salary) over w as fund
from employees
where city = 'Самара'
window w as (partition by department)
order by department, salary, id;
Фильтр сработал. Вот только значения fund отличаются от ожидаемых:
┌──────────┬────────┬──────┐
│ name │ salary │ fund │
├──────────┼────────┼──────┤
│ Дарья │ 70 │ 148 │
│ Борис │ 78 │ 148 │
│ Елена │ 84 │ 502 │
│ Леонид │ 104 │ 502 │
│ Григорий │ 96 │ 292 │
└──────────┴────────┴──────┘┌──────────┬────────┬──────┐
│ name │ salary │ fund │
├──────────┼────────┼──────┤
│ Дарья │ 70 │ 148 │
│ Борис │ 78 │ 148 │
│ Елена │ 84 │ 188 │
│ Леонид │ 104 │ 188 │
│ Григорий │ 96 │ 96 │
└──────────┴────────┴──────┘Все дело в порядке выполнения операций. Вот в какой последовательности действует движок, когда выполняет запрос:
- Взять нужные таблицы (
from) и соединить их при необходимости (join). - Отфильтровать строки (
where). - Сгруппировать строки (
group by). - Отфильтровать результат группировки (
having). - Взять конкретные столбцы из результата (
select). - Рассчитать значения оконных функций (
function() over window). - Отсортировать то, что получилось (
order by).
Таким образом, окна отрабатывают предпоследним шагом, уже после фильтрации и группировки результатов. Поэтому в нашем запросе fund отражает не сумму всех зарплат по департаменту, а сумму только по самарским сотрудникам.
Решение — использовать подзапрос с окном и фильтровать его в основном запросе:
with emp as (
select
name, city, salary,
sum(salary) over w as fund
from employees
window w as (partition by department)
order by department, salary, id
)
select name, salary, fund
from emp where city = 'Самара';
Описание окна
До сих пор мы описывали окно в блоке window и ссылались на него в выражении over:
select
name, department, salary,
count(*) over w as emp_count,
sum(salary) over w as fund
from employees
window w as (partition by department)
order by department, salary, id;
Это не единственный способ. SQL разрешает вообще не использовать window и описывать окно прямо внутри over:
select
name, department, salary,
count(*) over (partition by department) as emp_count,
sum(salary) over (partition by department) as fund
from employees
order by department, salary, id;
Мне больше нравится вариант с window — его легче читать, и можно явно переиспользовать окно. Но в документации часто встречается определение окна внутри over, поэтому не удивляйтесь, когда увидите его.
Кстати, определение окна может быть пустым:
select
name, department, salary,
count(*) over () as emp_count,
sum(salary) over () as fund
from employees
order by department, salary, id;
Такое окно включает все строки, так что emp_count покажет общее количество сотрудников, а fund — общий фонд оплаты труда по всем записям employees.
✎ Задачка: Порядок выполнения (+ еще одна)
Только практика превращает абстрактные знания в навыки. Поэтому я рекомендую не просто читать эту статью, а проходить курс или книгу — в них достаточно упражнений, чтобы уверенно освоить «окошки».
Если вас пока устраивает одна теория — продолжим.
Функции агрегации
Оконные функции агрегации:
| Функция | Описание |
|---|---|
min(value) | минимальное value среди строк секции окна |
max(value) | максимальное value |
count(value) | количество value, не равных null |
avg(value) | среднее значение по всем value |
sum(value) | сумма значений value |
group_concat(value, separator) | соединение значений value через разделитель separator (SQLite и MySQL) |
string_agg(value, separator) | аналог group_concat() в PostgreSQL и MS SQL |
Так держать
Мы разобрались, как считать фиксированные агрегаты в окнах. На следующем уроке займемся скользящими агрегатами!
Записаться на курс или купить книгу (скоро)