Оконные функции SQL: смещение
Это фрагмент моего курса Оконные функции SQL с пошаговым изложением, наглядными иллюстрациями и практическими упражнениями.
На предыдущем уроке мы разобрали оконные функции ранжирования.
Сравнение со смещением — это когда мы смотрим, в чем разница между соседними значениями. Например, сравниваем страны, которые занимают 5 и 6 место в мировом рейтинге ВВП — сильно ли отличаются? А если сравнить 1 и 6 место?
Сюда же попадают задачи, в которых мы сравниваем значение из набора с границами набора. Например, есть 100 лучших теннисисток мира. Мария Саккари занимает в рейтинге 10 место. Как ее показатели соотносятся со спортсменкой, которая занимает 1 место? А с той, кто занимает 100 место?
Мы будем сравнить сотрудников из таблицы employees:
┌────┬──────────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼──────────┼────────┼────────────┼────────┤
│ 11 │ Дарья │ Самара │ hr │ 70 │
│ 12 │ Борис │ Самара │ hr │ 78 │
│ 21 │ Елена │ Самара │ it │ 84 │
│ 22 │ Ксения │ Москва │ it │ 90 │
│ 23 │ Леонид │ Самара │ it │ 104 │
│ 24 │ Марина │ Москва │ it │ 104 │
│ 25 │ Иван │ Москва │ it │ 120 │
│ 31 │ Вероника │ Москва │ sales │ 96 │
│ 32 │ Григорий │ Самара │ sales │ 96 │
│ 33 │ Анна │ Москва │ sales │ 100 │
└────┴──────────┴────────┴────────────┴────────┘
Содержание:
- Сравнение с соседями
- Сравнение с границами
- Окно, секция, фрейм
- Сравнение с границами, окончание
- Функции смещения
- Так держать
Сравнение с соседями
Упорядочим сотрудников по возрастанию зарплаты и проверим, велик ли разрыв между соседями:
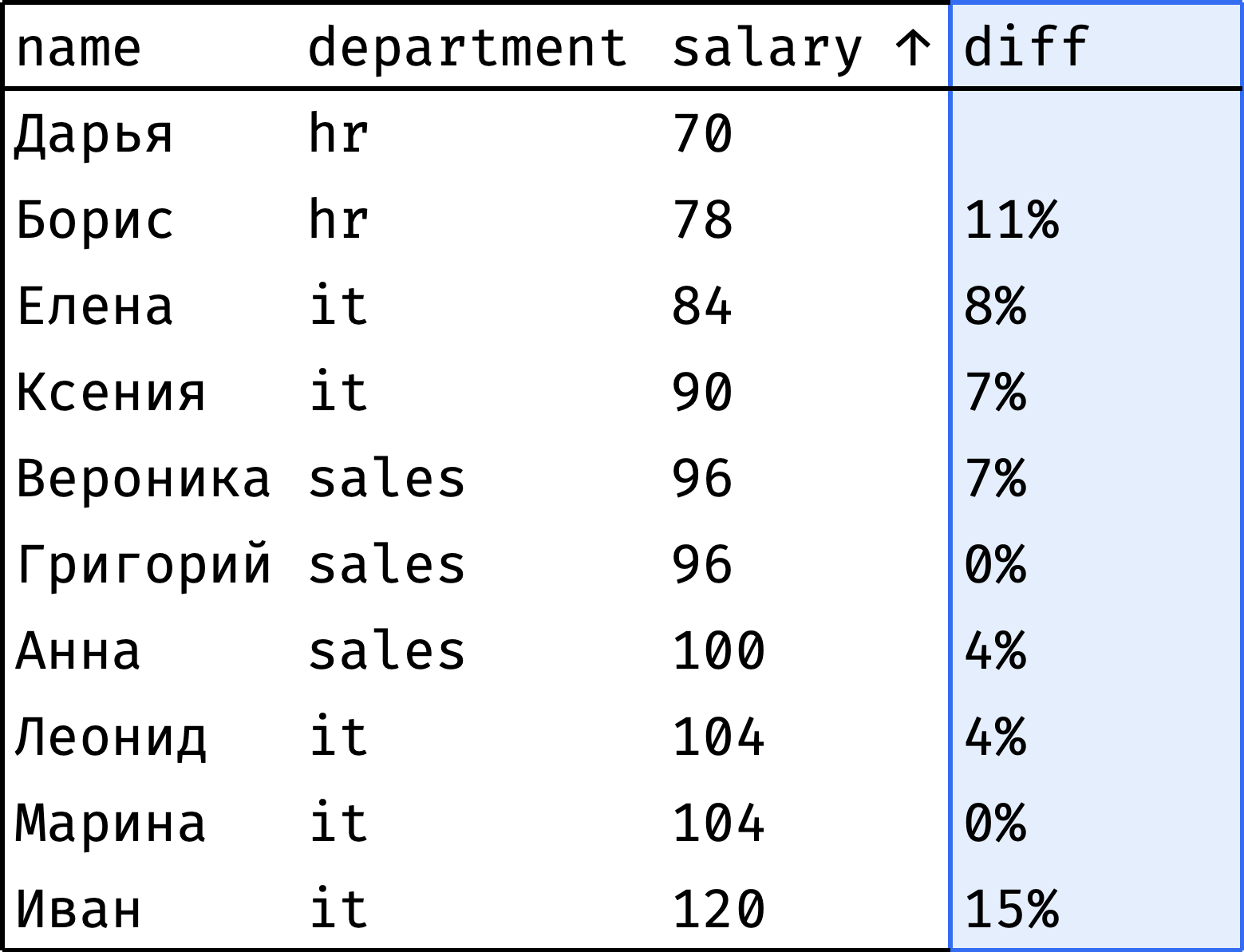
Столбец diff показывает, на сколько процентов зарплата сотрудника отличается от предыдущего коллеги. Видно, что больших разрывов нет. Самые крупные — между Дарьей и Борисом (11%) и Мариной и Иваном (15%).
Как перейти от «было» к «стало»?
Сначала отсортируем таблицу по возрастанию зарплаты:
select
name, department, salary,
null as prev
from employees
order by salary, id;
Теперь пройдем от первой строчки до последней, на каждом шаге «подтягивая» зарплату предыдущего сотрудника:
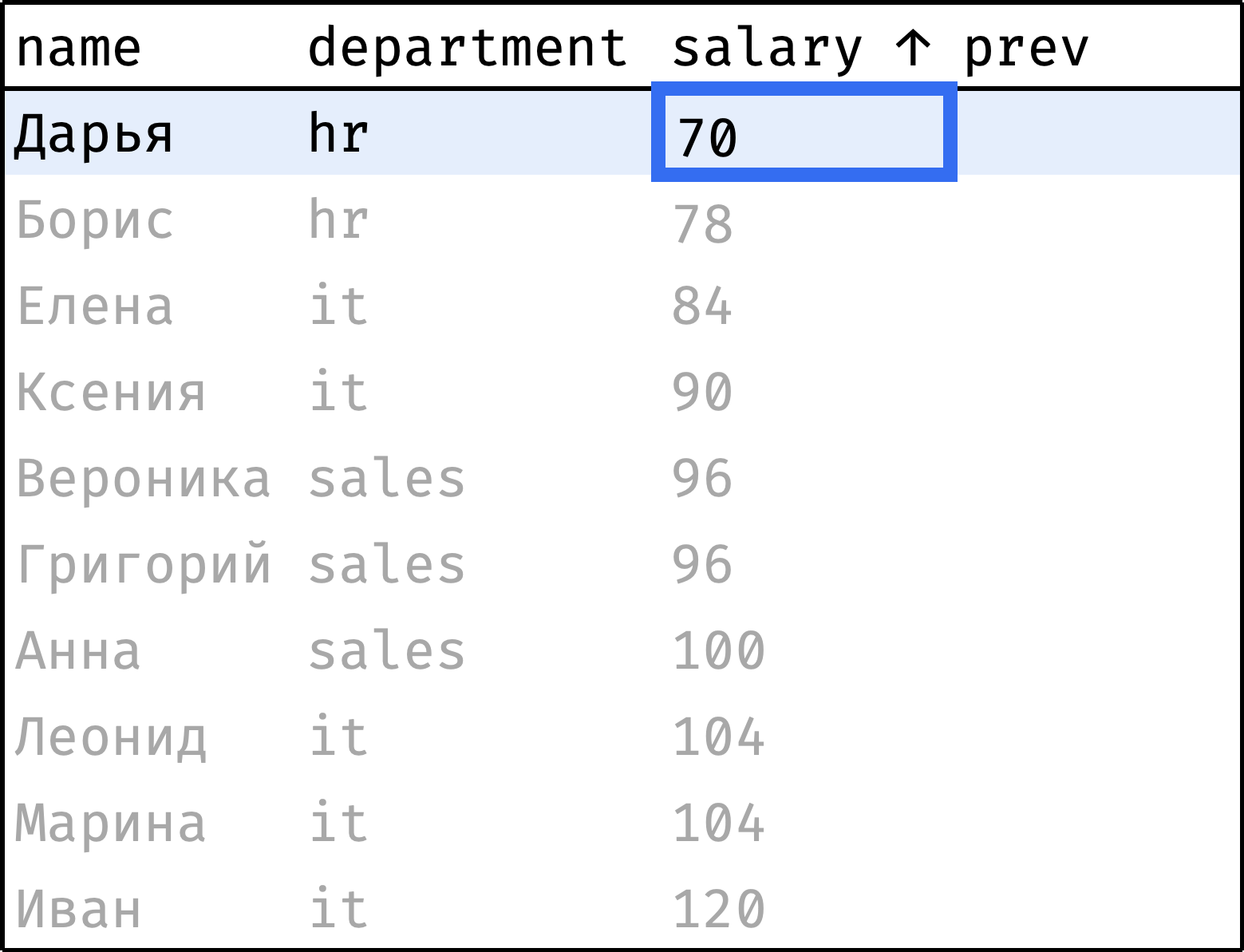
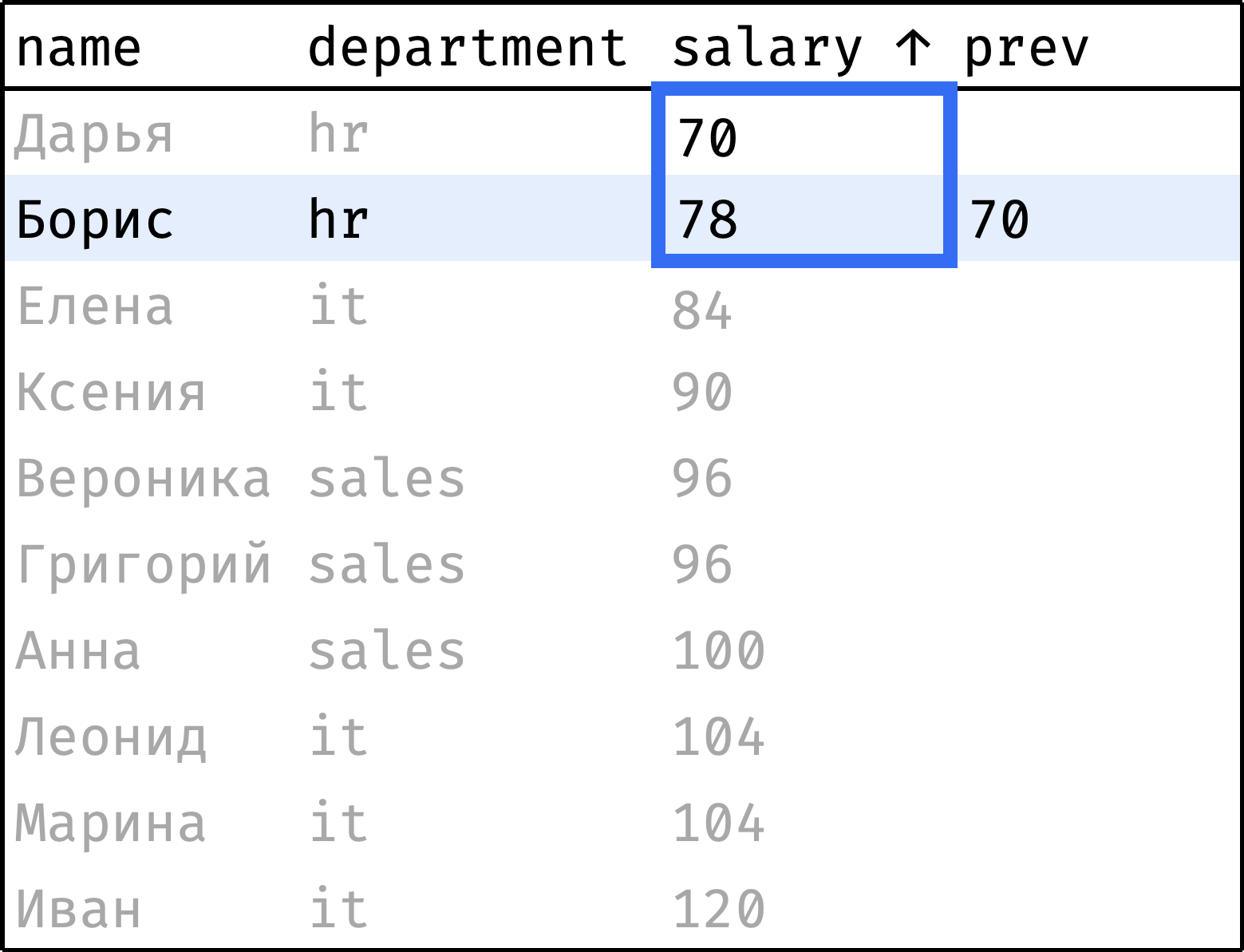
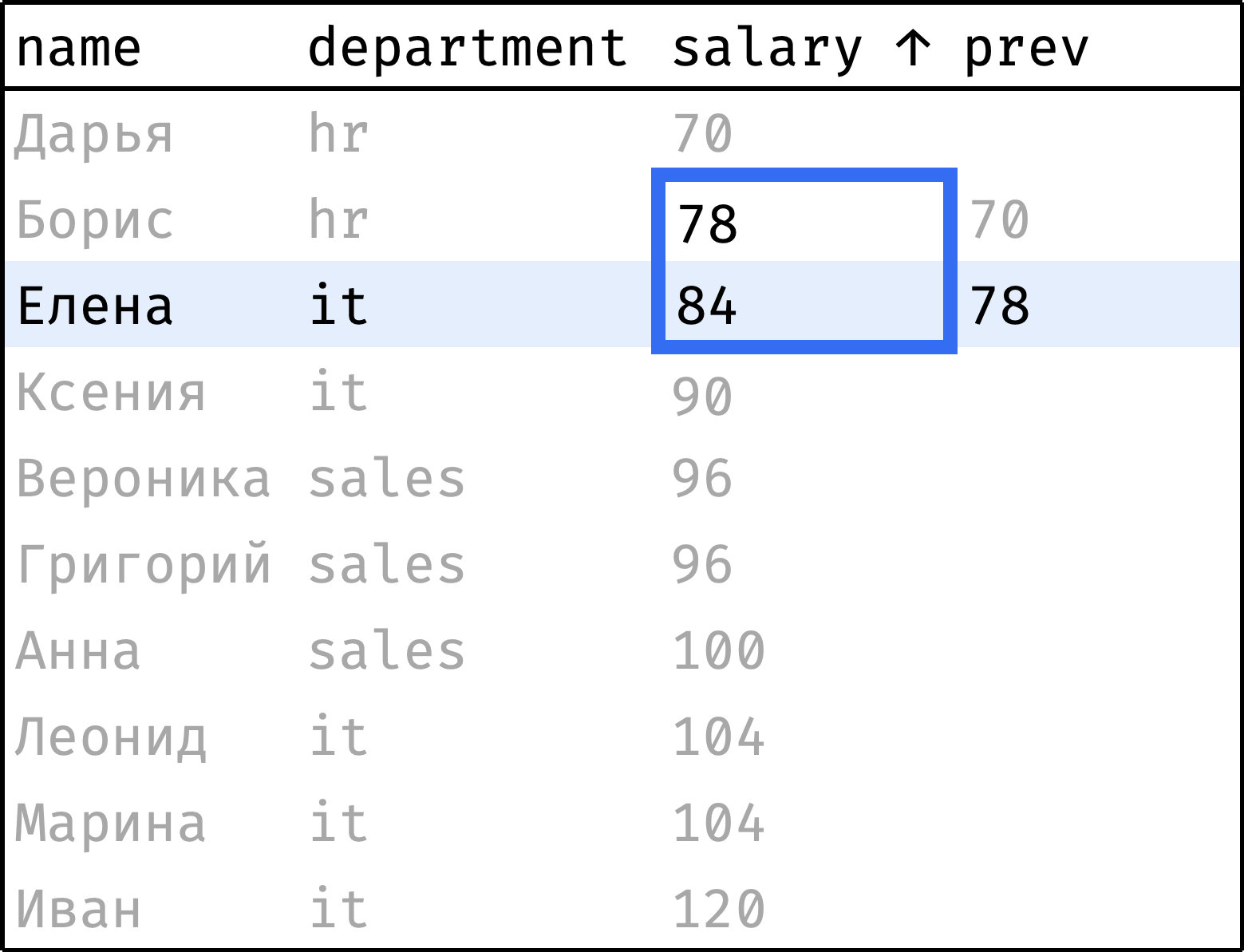
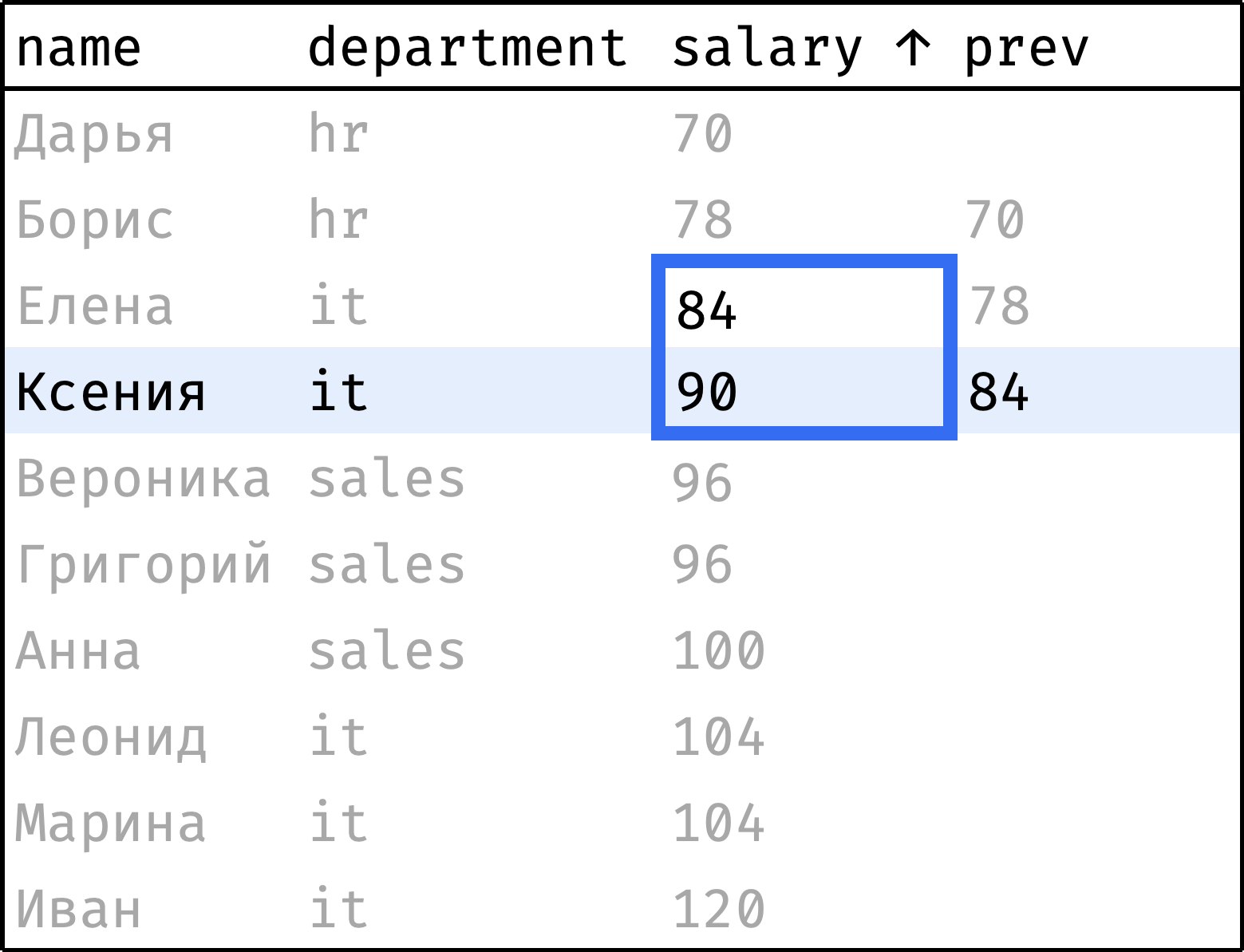
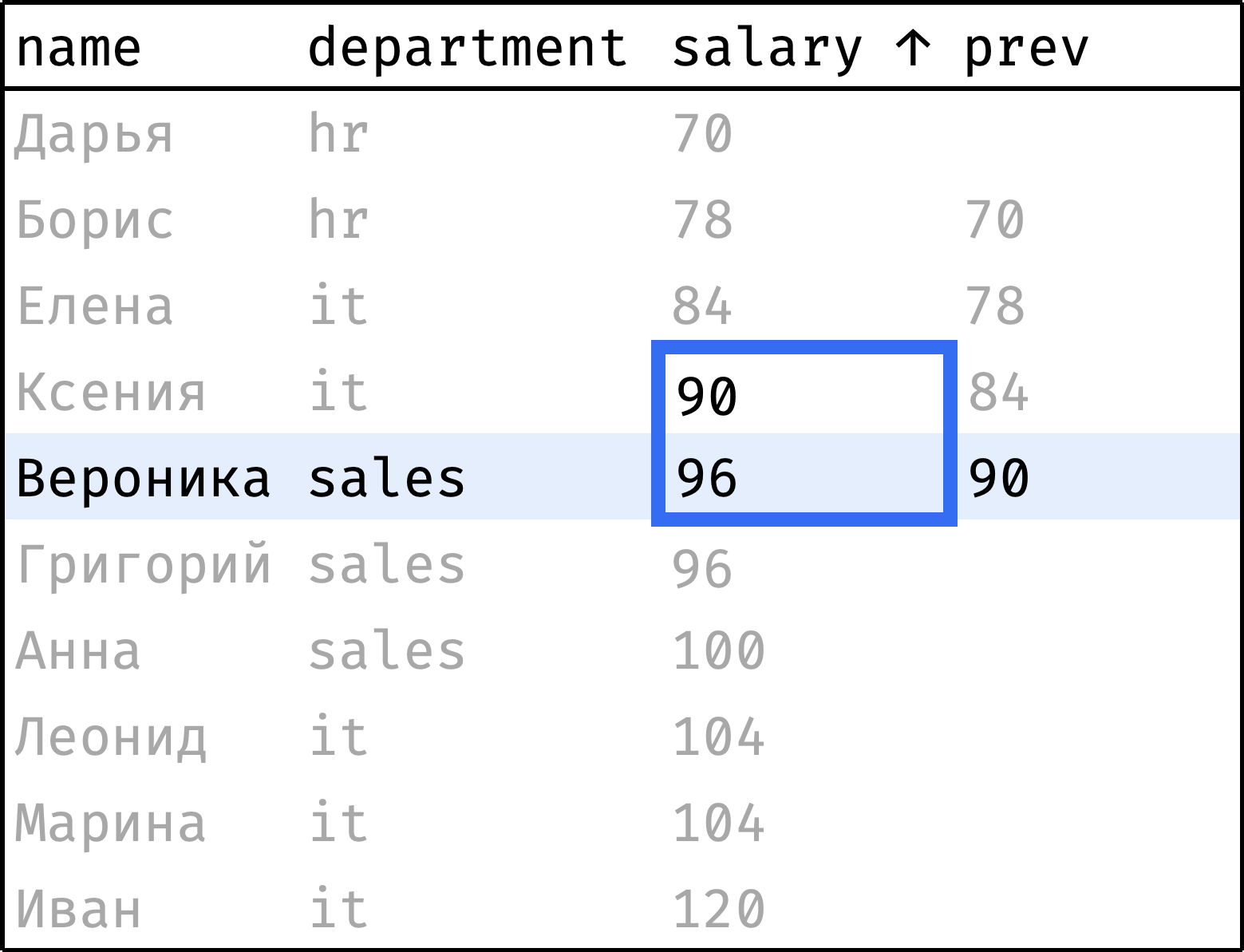
и так далее...
Одной гифкой:

Видно, что окно в данном случае охватывает текущую и предыдущую запись. Оно сдвигается вниз на каждом шаге, скользит. Это логичная трактовка происходящего, и задать скользящее окно в SQL можно. Но у таких окон более сложный синтаксис, поэтому отложим их до главы о скользящих агрегатах.
Вместо этого возьмем более простое и знакомое нам окно — все записи, упорядоченные по возрастанию salary:
А чтобы на каждом шаге подтягивать зарплату предыдущего сотрудника, будем использовать оконную функцию lag():
lag(salary, 1) over w
Функция lag() возвращает значение из указанного столбца, отстоящее от текущего на указанное количество записей назад. В нашем случае — salary от предыдущей записи.
Добавим окно и оконную функцию в исходный запрос:
select
id, name, department, salary,
lag(salary, 1) over w as prev
from employees
window w as (order by salary, id)
order by salary, id;
Столбец prev показывает зарплату предыдущего сотрудника. Осталось посчитать разницу между prev и salary в процентах:
with emp as (
select
id, name, department, salary,
lag(salary, 1) over w as prev
from employees
window w as (order by salary, id)
)
select
name, department, salary,
round((salary - prev)*100.0 / prev) as diff
from emp
order by salary, id;
Можно избавиться от промежуточной таблицы emp, подставив вместо prev вызов оконной функции:
select
name, department, salary,
round(
(salary - lag(salary, 1) over w)*100.0 / lag(salary, 1) over w
) as diff
from employees
window w as (order by salary, id)
order by salary, id;
Здесь мы заменили prev → lag(salary, 1) over w. Конструкцию вида function_name(...) over window_name движок заменяет на конкретное значение, которое вернула функция. Так что оконную функцию можно вызывать прямо внутри вычислений, и вы не раз встретите такие запросы в документации и примерах.
✎ Задачка: Зарплата соседнего сотрудника
Только практика превращает абстрактные знания в навыки. Поэтому я рекомендую не просто читать эту статью, а проходить курс или книгу — в них достаточно упражнений, чтобы уверенно освоить «окошки».
Если вас пока устраивает одна теория — продолжим.
Сравнение с границами
Посмотрим, как зарплата сотрудника соотносится с минимальной и максимальной зарплатой в его департаменте:
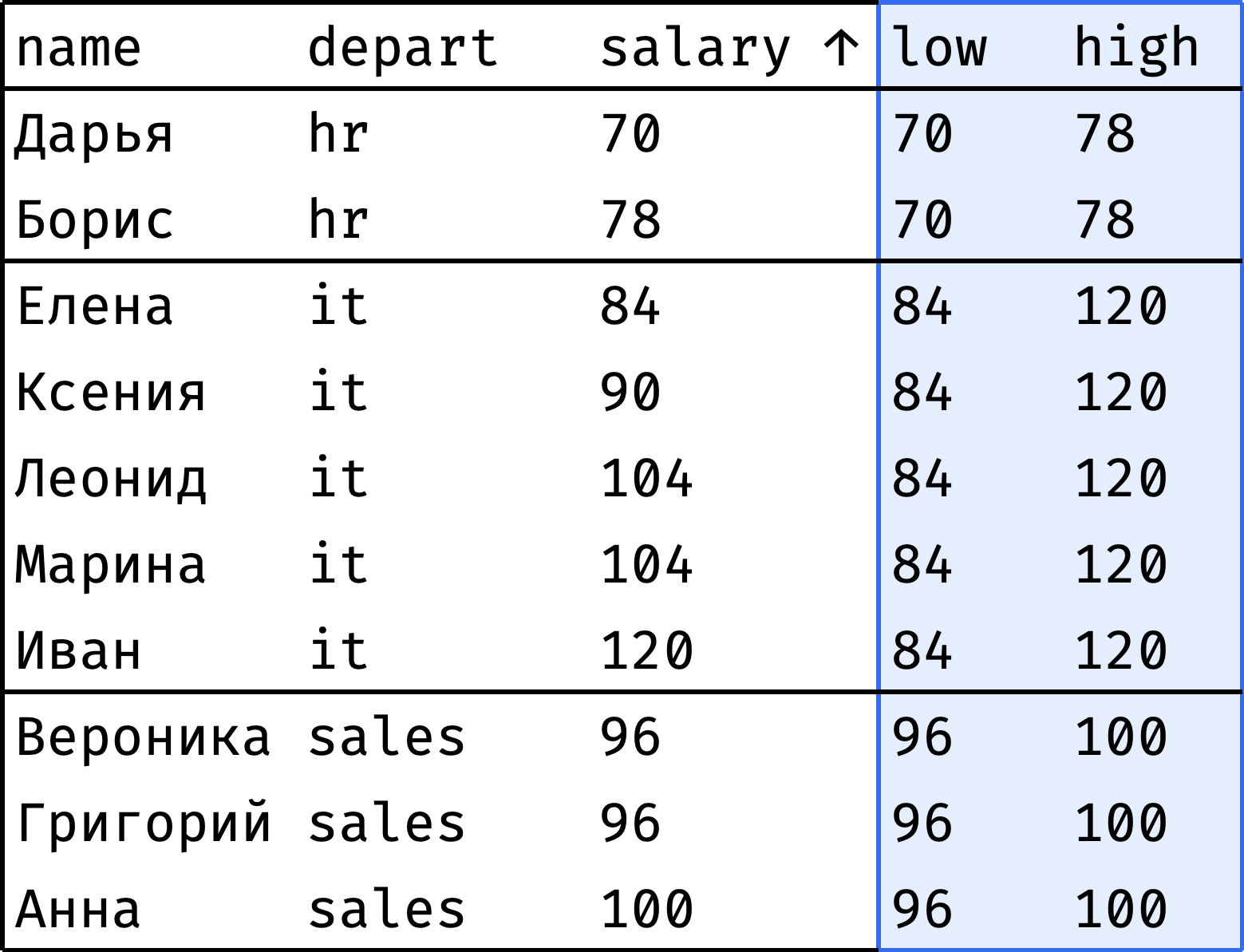
Для каждого сотрудника столбец low показывает минимальную зарплату родного департамента, а столбец high — максимальную.
Как перейти от «было» к «стало»?
Сначала отсортируем таблицу по департаментам, а внутри департамента — по возрастанию зарплаты:
select
name, department, salary,
null as low,
null as high
from employees
order by department, salary, id;
Теперь пройдем от первой строчки до последней, на каждом шаге «подтягивая» наименьшую и наибольшую зарплаты в отделе:
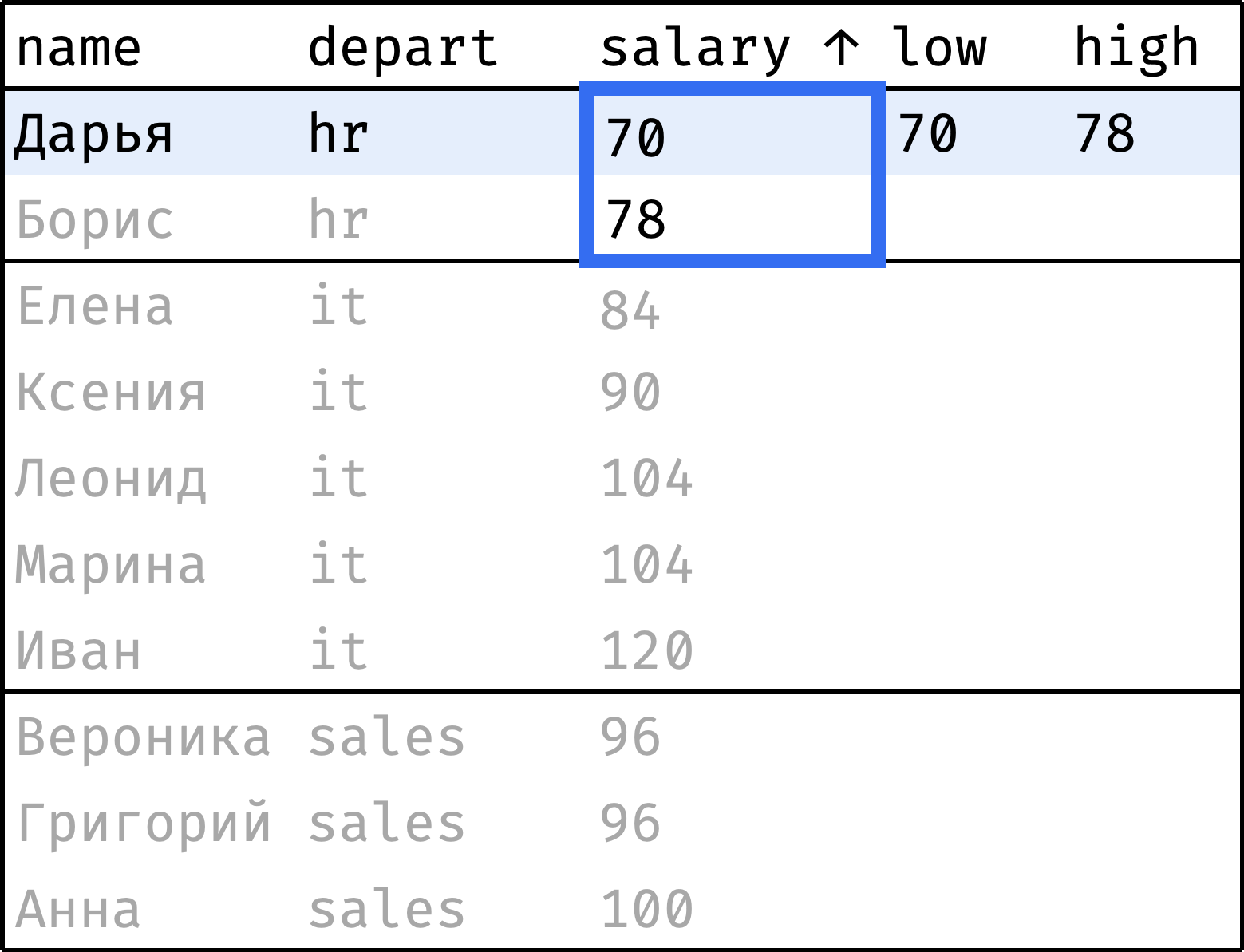
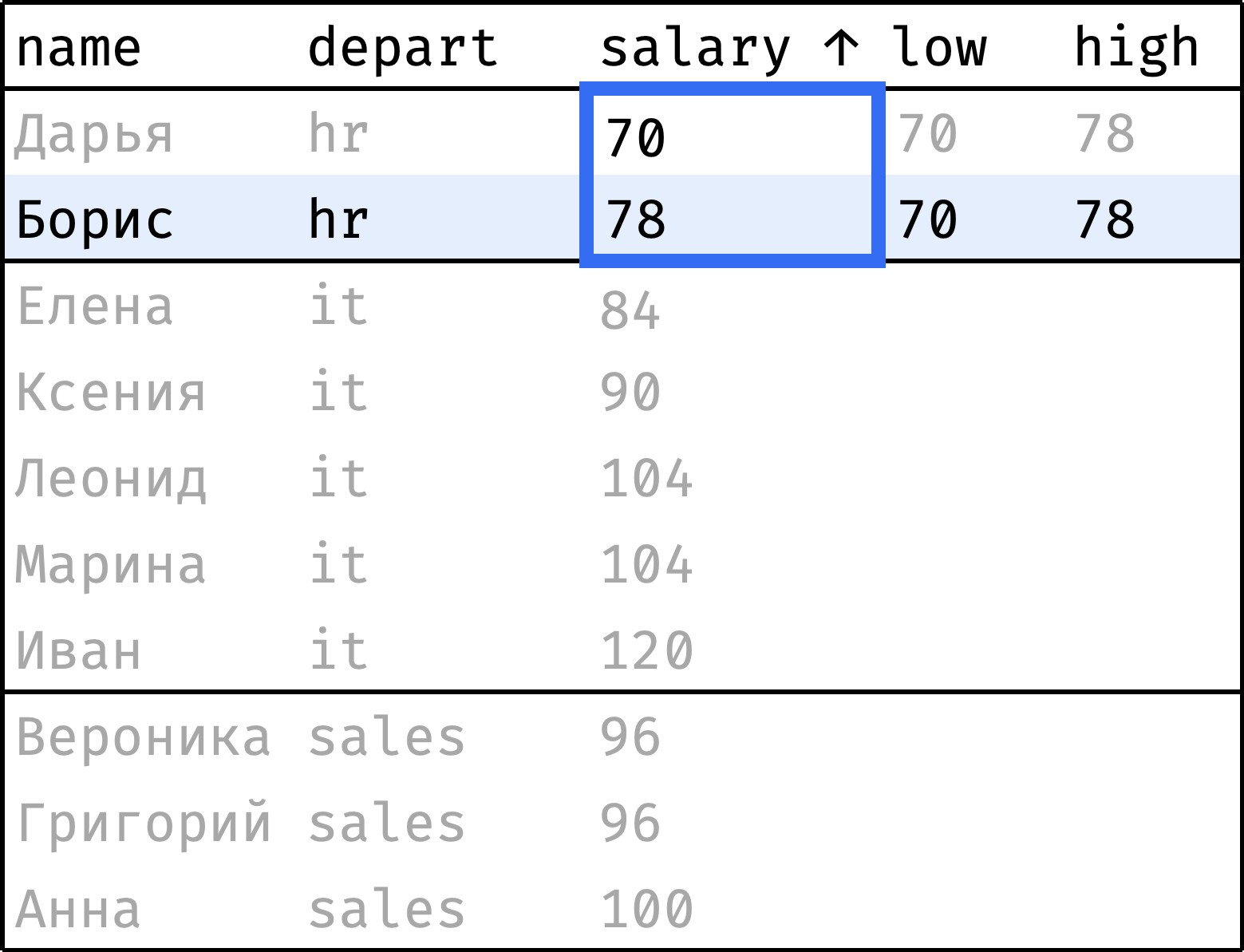
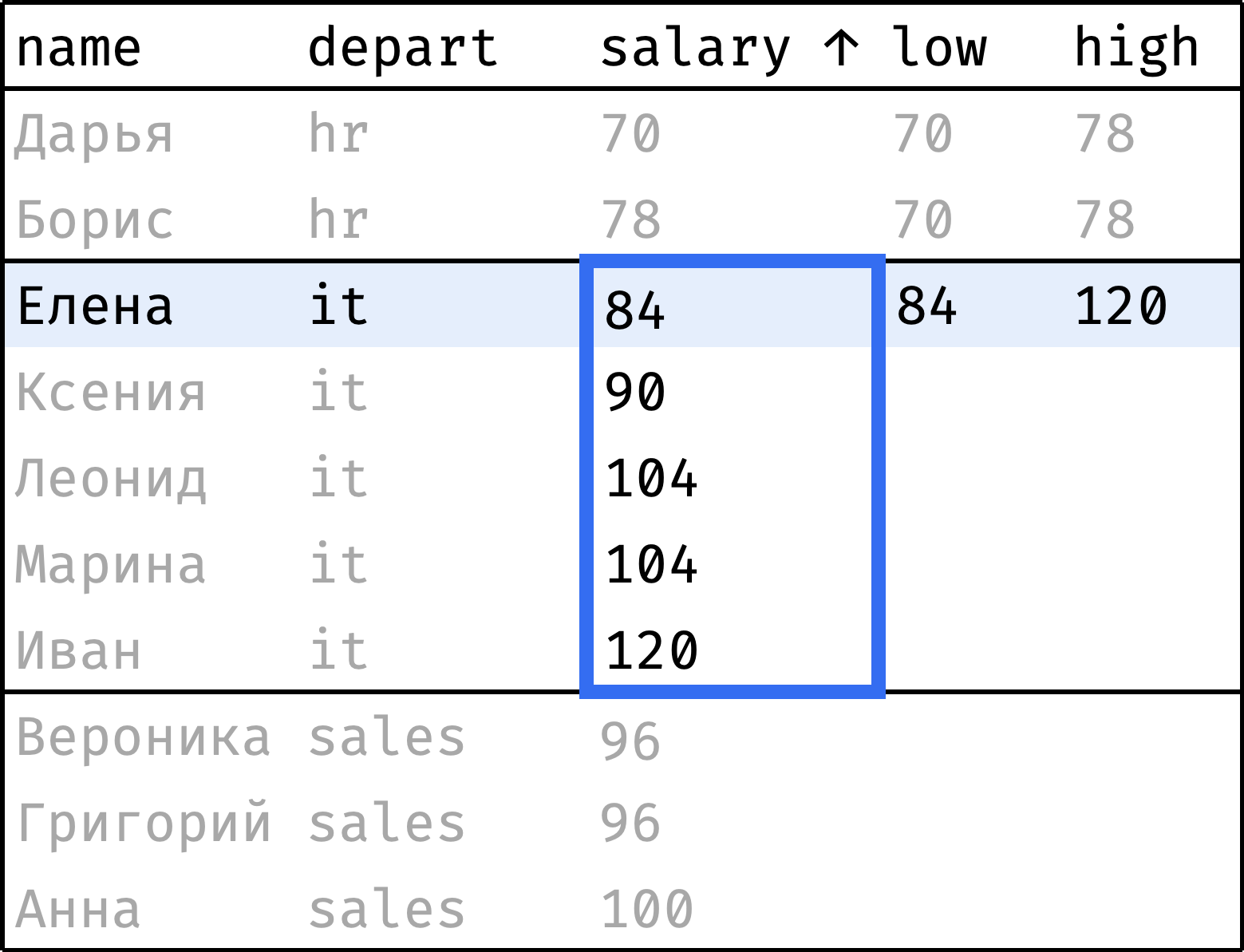
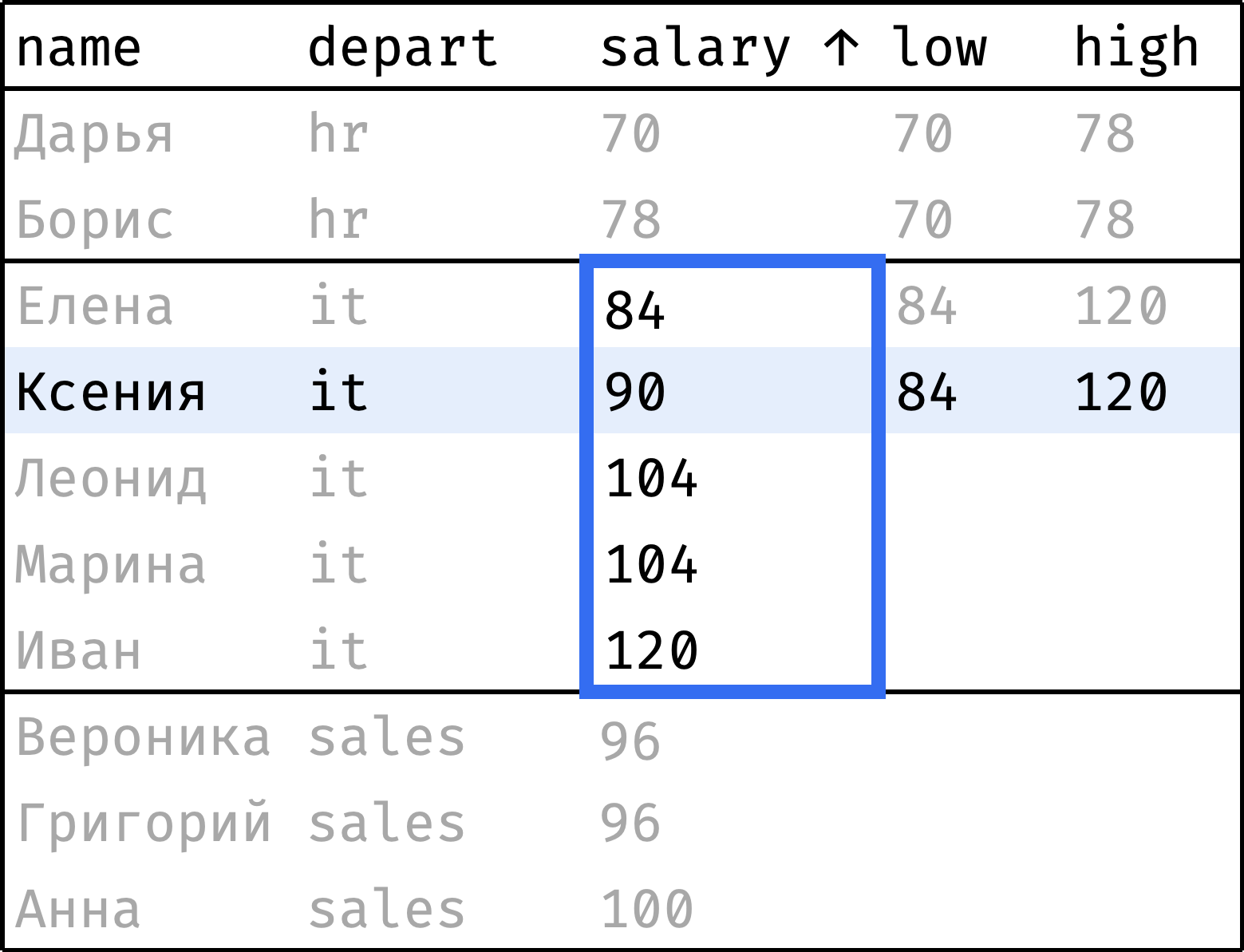
и так далее...
Одной гифкой:

Окно состоит из трех секций. Секция на каждом шаге охватывает весь департамент сотрудника. Записи при этом упорядочены по возрастанию зарплаты внутри департамента, чтобы минимальная и максимальная зарплаты всегда находились на границах секции:
window w as (
partition by department
order by salary
)
Хотелось бы воспользоваться функциями lag() и lead(), чтобы получить диапазон зарплат в отделе. Но они заглядывают на фиксированное количество записей назад или вперед. Нам же нужно нечто другое:
low— зарплата первого сотрудника, входящего в секцию окна;high— зарплата последнего сотрудника, входящего в секцию.
К счастью, есть оконные функции ровно для этого:
first_value(salary) over w as low,
last_value(salary) over w as high
Добавим окно и оконную функцию в исходный запрос:
select
name, department, salary,
first_value(salary) over w as low,
last_value(salary) over w as high
from employees
window w as (
partition by department
order by salary
)
order by department, salary, id;
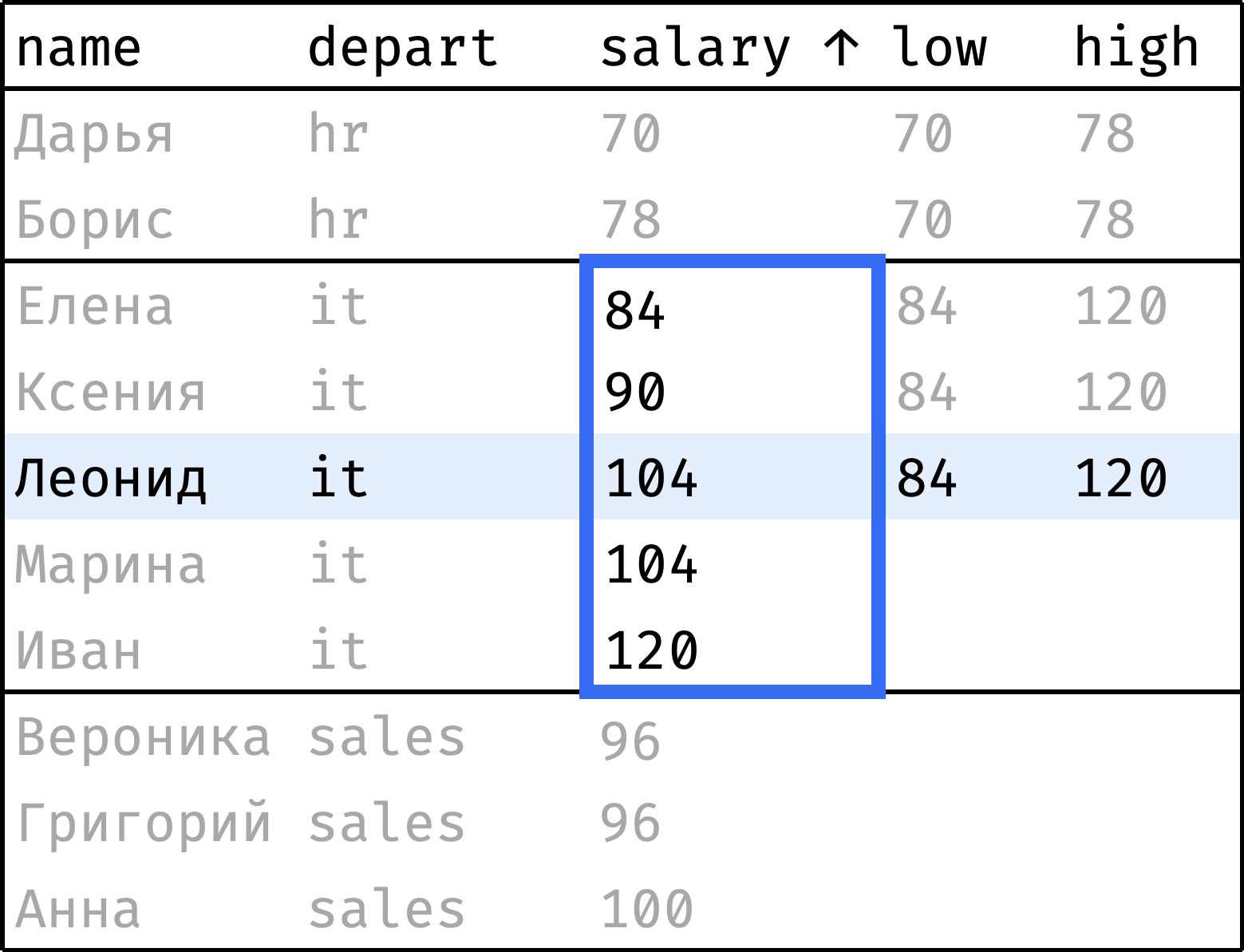
low рассчитался корректно, а вот с high какая-то ерунда. Вместо того чтобы равняться максимальной зарплате департамента, он меняется от сотрудника к сотруднику. Что ж, давайте разбираться.
Окно, секция, фрейм
До сих пор все было логично:
- есть окно, которое состоит из одной или нескольких секций;
- внутри секции записи упорядочены по конкретному столбцу.
На предыдущем шаге мы разделили окно на три секции — по департаментам, и упорядочили записи внутри секций по зарплате:
window w as (
partition by department
order by salary
)
Допустим, движок выполняет запрос, и текущая запись — Леонид из it-отдела. Мы ожидаем, что first_value() вернет первую запись it-секции (salary = 84), а last_value() — последнюю (salary = 120):
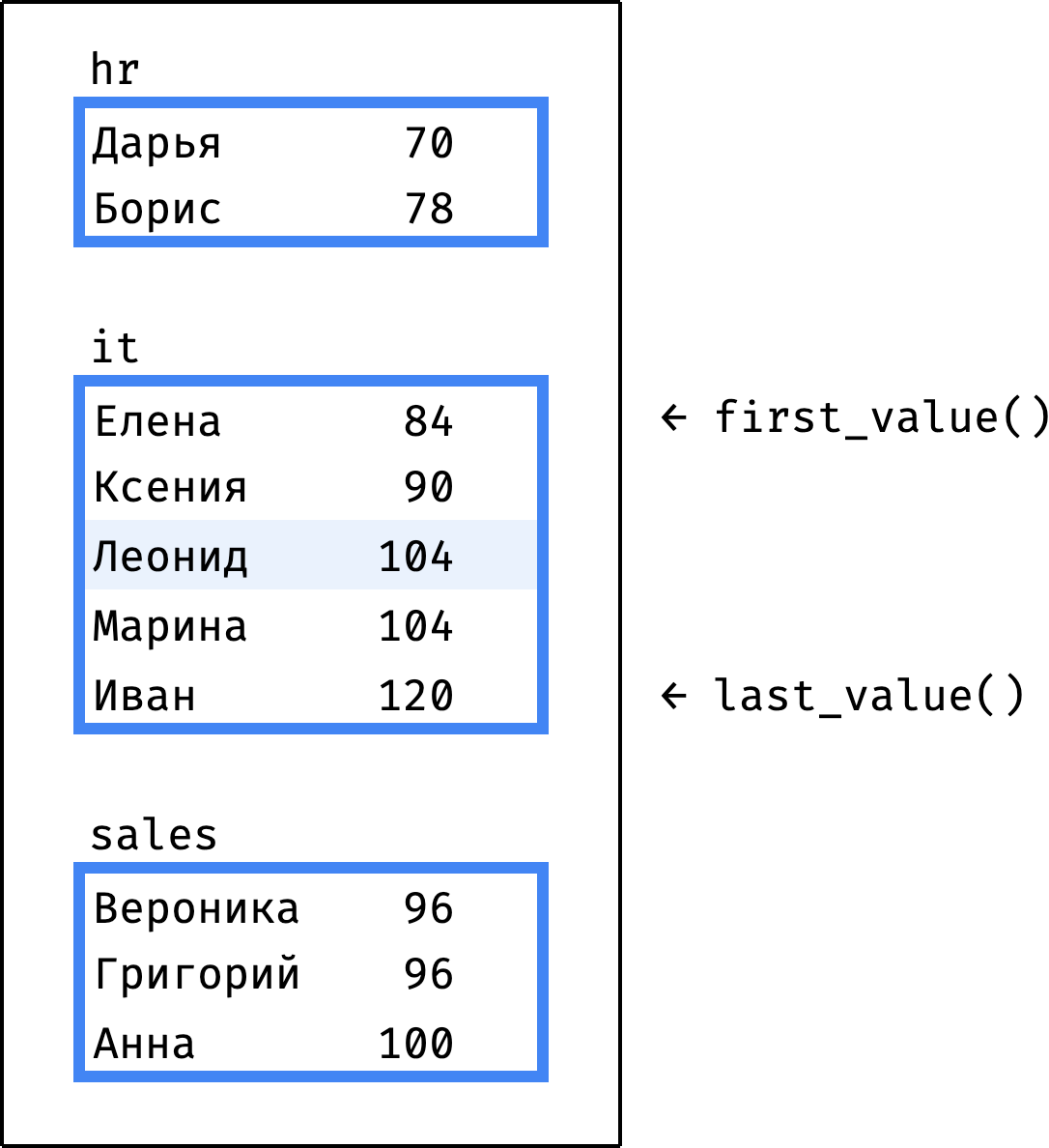

Дело в том, что функции first_value() и last_value() работают не просто с секцией окна. Они работают с фреймом внутри секции:
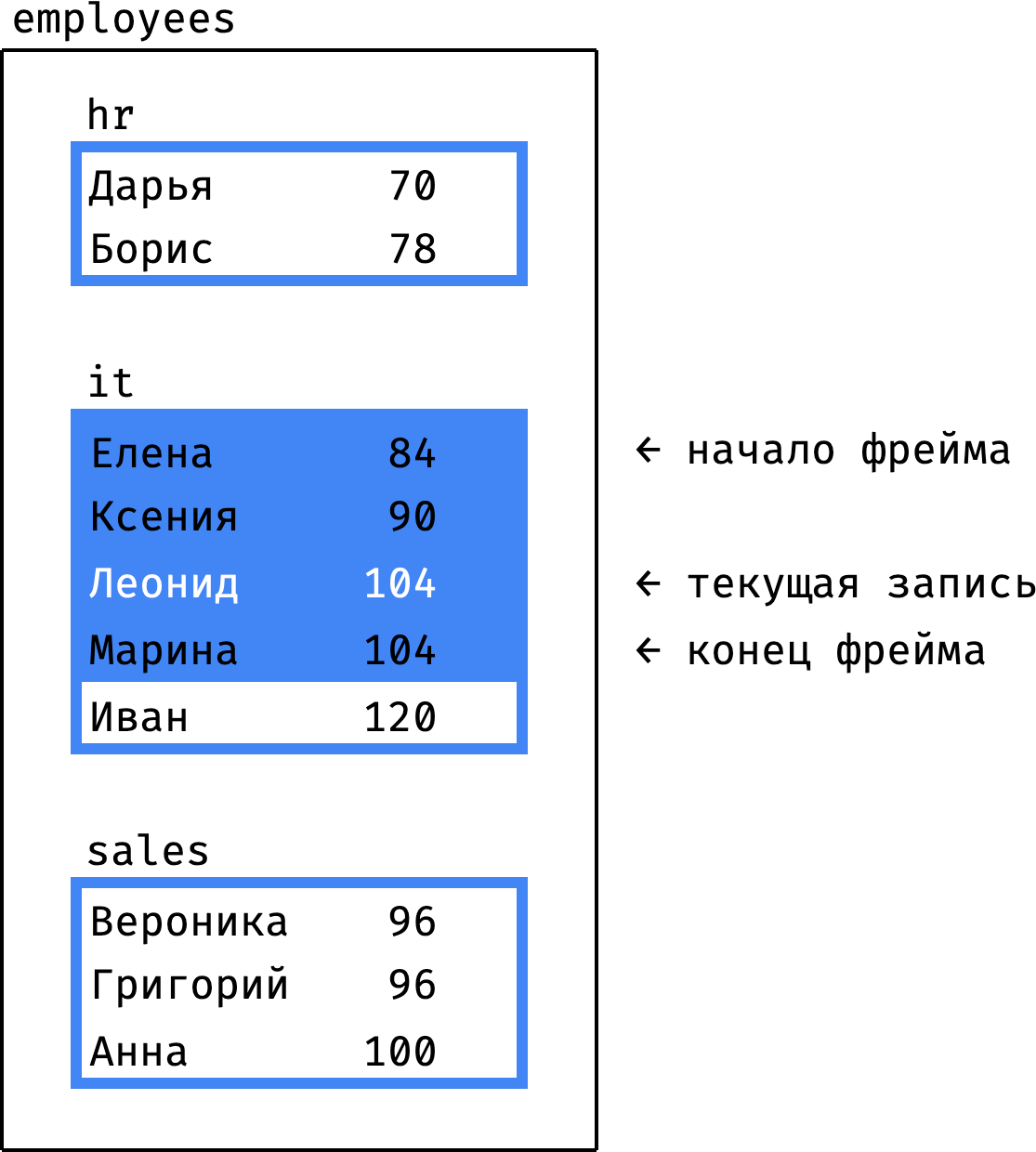
Фрейм находится в той же секции, где текущая запись (Леонид):
- начало фрейма = начало секции (Елена);
- конец фрейма = последняя запись со значением
salary, равным текущей записи (Марина).
Где заканчивается фрейм
Если с началом фрейма все понятно, то с концом у людей часто возникают вопросы. Рассмотрим несколько примеров, чтобы стало понятнее. Текущая запись во всех примера — Леонид.
Елена 84 ← начало фрейма
Ксения 90
Леонид 104 ← текущая запись
Марина 104 ← конец фрейма
Иван 120Конец фрейма — последняя запись со значением зарплаты, равным текущей записи. Текущая запись — Леонид с зарплатой 104. Последняя запись с зарплатой 104 — Марина. Значит, конец фрейма — Марина.
Елена 84 ← начало фрейма
Ксения 90
Леонид 104 ← текущая запись и конец фрейма
Марина 110
Иван 120Допустим, Марине повысили зарплату до 110. Текущая запись — Леонид с зарплатой 104. Последняя запись с зарплатой 104 — тоже Леонид. Значит, конец фрейма — Леонид.
Елена 84 ← начало фрейма
Ксения 90
Леонид 104 ← текущая запись
Марина 104
Иван 104 ← конец фреймаДопустим, Ивану понизили зарплату до 104. Текущая запись — Леонид с зарплатой 104. Последняя запись с зарплатой 104 — Иван. Значит, конец фрейма — Иван.
Секция фиксирована, фрейм же зависит от текущей записи и постоянно меняется:


first_value() возвращает первую строчку фрейма, а не секции. Но поскольку начало фрейма совпадает с началом секции, функция отрабатывает как мы ожидали.
last_value() возвращает последнюю строчку фрейма, а не секции. Именно поэтому в нашем запросе она вернула не максимальную зарплату для каждого отдела, а какую-то ерунду.
Чтобы last_value() работала как мы ожидаем, придется «прибить» границы фрейма к границам секции. Тогда для каждой секции фрейм будет в точности совпадать с ней:
Подытожим, как работают first_value() и last_value():
- Есть окно, которое состоит из одной или нескольких секций (
partition by department). - Внутри секции записи упорядочены по конкретному столбцу (
order by salary). - У каждой записи в секции свой фрейм. По умолчанию начало фрейма совпадает с началом секции, а конец для каждой записи свой.
- Конец фрейма можно приклеить к концу секции, чтобы фрейм в точности совпадал с секцией.
- Функция
first_value()возвращает значение из первой строки фрейма. - Функция
last_value()возвращает значение из последней строки фрейма.
Теперь разберемся, как прибить фрейм к окну — и закончим с запросом по диапазону зарплат в департаментах.
Примечание. Если не совсем поняли, что такое фрейм и как он формируется — ничего страшного. Фреймы — одна из самых сложных тем в «окошках», и за один прием их не объяснить. Мы будем изучать фреймы на протяжении всего курса, и постепенно все разберем.
Сравнение с границами, окончание
Возьмем наше окно:
window w as (
partition by department
order by salary
)
И настроим его, чтобы фрейм в точности совпадал с секцией (департаментом):
window w as (
partition by department
order by salary
rows between unbounded preceding and unbounded following
)
Не будем сейчас разбирать конструкцию rows between — ее время придет в одном из следующих уроков. Важно, что благодаря ей фрейм совпадает с секцией, а значит last_value() вернет максимальную зарплату по департаменту:
select
name, department, salary,
first_value(salary) over w as low,
last_value(salary) over w as high
from employees
window w as (
partition by department
order by salary
rows between unbounded preceding and unbounded following
)
order by department, salary, id;
Теперь движок заполняет low и high так же, как мы делали это вручную:
✎ Задачка: Процент от максимальной зарплаты в городе
Только практика превращает абстрактные знания в навыки. Поэтому я рекомендую не просто читать эту статью, а проходить курс или книгу — в них достаточно упражнений, чтобы уверенно освоить «окошки».
Если вас пока устраивает одна теория — продолжим.
Функции смещения
Оконные функции смещения:
| Функция | Описание |
|---|---|
lag(value, offset) | значение value из строки, отстоящей на offset строк назад от текущей |
lead(value, offset) | значение value из строки, отстоящей на offset строк вперед от текущей |
first_value(value) | значение value из первой строки фрейма |
last_value(value) | значение value из последней строки фрейма |
nth_value(value, n) | значение value из n-й строки фрейма |
lag() и lead() действуют относительно текущей строки, заглядывая вперед или назад на указанное количество строк.

first_value(), last_value() и nth_value() действуют относительно границ фрейма, выбирая указанную строку в пределах фрейма.

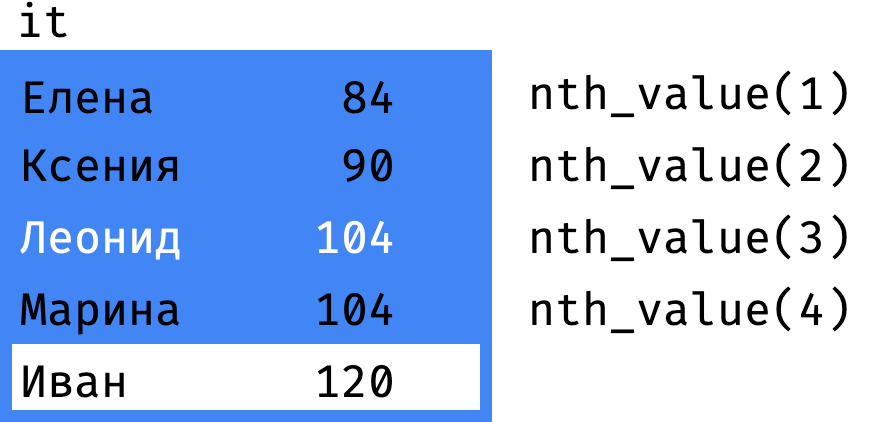
Чтобы границы фрейма совпадали с границами секции (или всего окна, если секция одна) — используют такую конструкцию в определении окна:
rows between unbounded preceding and unbounded following
Так держать
Мы разобрались, как сравнивать строки с соседями и границами окна. На следующем уроке будем агрегировать данные!
Записаться на курс или купить книгу (скоро)