Оконные функции SQL: ранжирование
Это фрагмент моего курса Оконные функции SQL с пошаговым изложением, наглядными иллюстрациями и практическими упражнениями.
Ранжирование — это всевозможные рейтинги, начиная от призеров чемпионата мира по плаванию и заканчивая Forbes 500.
Мы же будем ранжировать сотрудников в игрушечной таблице employees:
┌────┬──────────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼──────────┼────────┼────────────┼────────┤
│ 11 │ Дарья │ Самара │ hr │ 70 │
│ 12 │ Борис │ Самара │ hr │ 78 │
│ 21 │ Елена │ Самара │ it │ 84 │
│ 22 │ Ксения │ Москва │ it │ 90 │
│ 23 │ Леонид │ Самара │ it │ 104 │
│ 24 │ Марина │ Москва │ it │ 104 │
│ 25 │ Иван │ Москва │ it │ 120 │
│ 31 │ Вероника │ Москва │ sales │ 96 │
│ 32 │ Григорий │ Самара │ sales │ 96 │
│ 33 │ Анна │ Москва │ sales │ 100 │
└────┴──────────┴────────┴────────────┴────────┘
Содержание:
- Оконная функция
- Сортировка окна и сортировка результатов
- Однозначность сортировки
- Несколько окон
- Секции окна
- Группы
- Функции ранжирования
- Так держать
Базы данных
Оконные функции в той или иной степени поддерживаются во всех современных реляционных СУБД. Курс тестировался на трех:
- MySQL 8.0.2+ (MariaDB 10.2+)
- PostgreSQL 11+
- SQLite 3.28+
Полнее всего окошки реализованы в PostgreSQL и SQLite. MySQL поддерживает основные возможности, но лишен некоторых более продвинутых.
Oracle 11g+, MS SQL 2012+ и Google BigQuery поддерживают «окошки» примерно так же, как MySQL. Так что если вы используете одну из них — книгу тоже будет полезна.
Вы можете использовать любую из перечисленных СУБД, если она у вас под рукой. Или использовать онлайн-песочницу.
Оконная функция
Составим рейтинг сотрудников по размеру заработной платы:
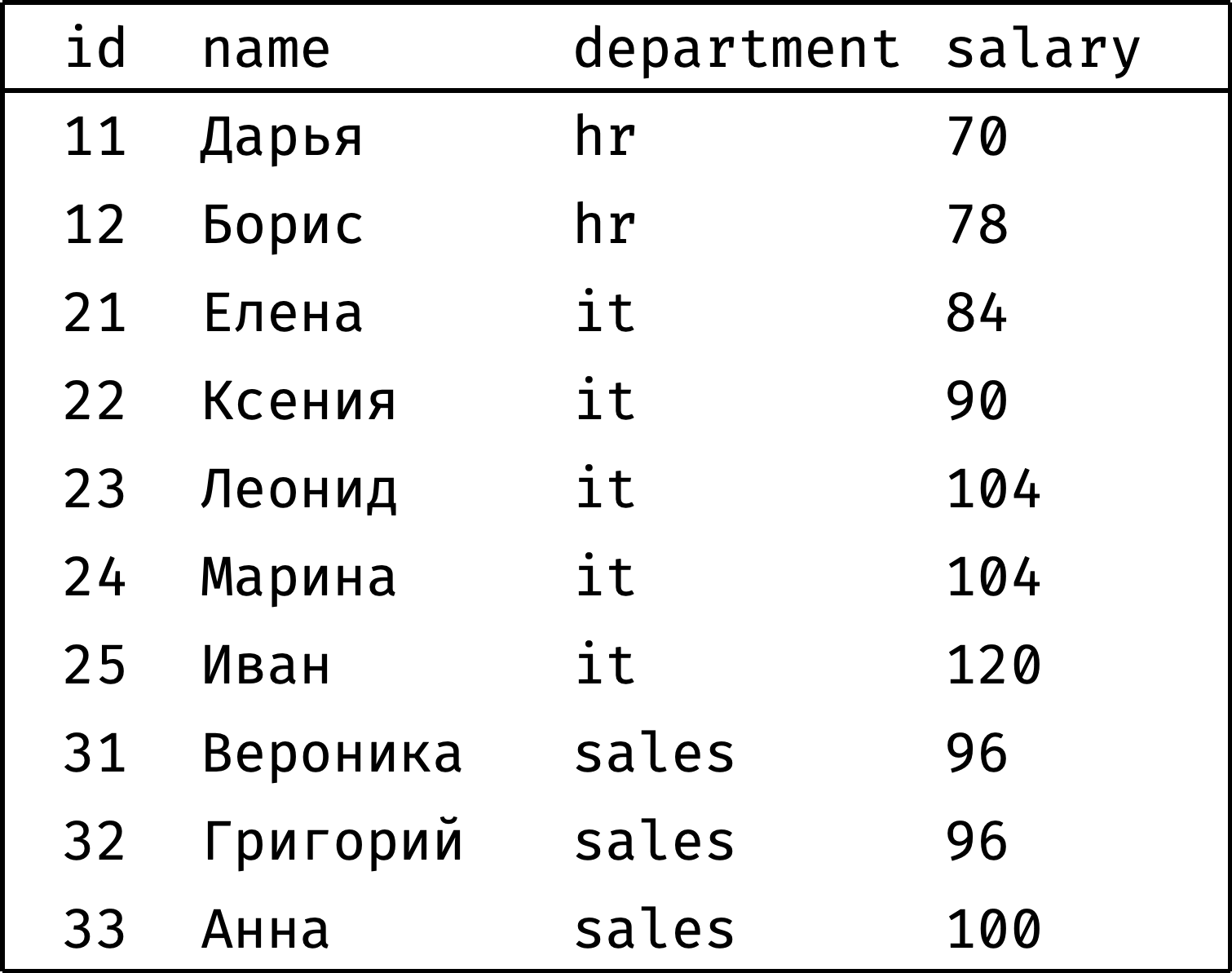
Обратите внимание — сотрудники с одинаковой зарплатой получили один и тот же ранг (Леонид и Марина, Вероника и Григорий).
Как перейти от «было» к «стало»?
Сначала отсортируем таблицу по убыванию зарплаты:
select
null as "rank",
name, department, salary
from employees
order by salary desc, id;
Теперь пройдем от первой строчки до последней и проставим ранг каждой записи. Начнем с 1 и будем увеличивать ранг каждый раз, когда значение salary меньше, чем у предыдущей записи:
и так далее...
Чтобы проставить ранг, достаточно на каждом шаге смотреть только на значения из столбца salary, выделенные синей рамкой. Назовем эти значения окном.
Попробуем описать содержимое окна словами:
- Это значения столбца
salary. - Они упорядочены от большего значения к меньшему.
Сформулируем то же самое на SQL:
window w as (order by salary desc)
window— ключевое слово, которое показывает, что дальше будет определение окна;w— название окна (может быть любым);(order by salary desc)— описание окна («значения столбцаsalary, упорядоченные по убыванию»).
Задача — посчитать ранг по окну w. На SQL это записывается как dense_rank() over w.
dense_rank() — это оконная функция, которая считает ранг по указанному окну. Логика dense_rank() такая же, как была у нас при ручном подсчете — начать с 1 и увеличивать ранг каждый раз, когда очередное значение из окна отличается от предыдущего.
Добавим окно и оконную функцию в исходный запрос:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by "rank", id;
Вот как движок выполняет такой запрос:
- Берет таблицу, указанную в
from. - Выбирает из нее все записи.
- Для каждой записи рассчитывает значение
dense_rank()с помощью окнаw. - Сортирует результат как указано в
order by.
Вот как отрабатывает шаг 3, на котором назначается ранг:
Конструкция window сама по себе ничего не делает с результатами запроса. Она только определяет окно, которое можно использовать (или не использовать) в запросе. Если убрать вызов dense_rank(), запрос отработает, как будто нет никаких окон:
select
null as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by salary desc, id;
Окно начинает работать только тогда, когда в select появляется оконная функция, которая его использует.
Оконные запросы в СУБД Oracle и MS SQL Server
Ни Oracle, ни SQL Server не поддерживают конструкцию window. Чтобы заставить работать оконный запрос в этих СУБД, перенесите описание окна внутрь инструкции over.
Не так:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by "rank", id;
А так:
select
dense_rank() over (
order by salary desc
) as "rank",
name, department, salary
from employees
order by "rank", id;Сортировка окна и сортировка результатов
При первом взгляде на «окошки» у людей часто возникают вопросы. Давайте их разберем.
Вот запрос, который считает рейтинг зарплат:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by "rank", id;
Оставим order by в окне, но уберем в основном запросе:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc);
Ничего не изменилось. Тогда зачем order by в основном запросе?
order by в окне задает сортировку окна, а order by в основном запросе — сортировку результатов уже после того, как отработало и окно, и все прочие части запроса.
Допустим, мы хотим проставить ранг по убыванию зарплаты, а отсортировать — наоборот, по возрастанию:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by salary asc;
Видно, что ранг проставился по сортировке окна (salary desc), а результат упорядочен по сортировке основного запроса (salary asc).
Если вообще не указать order by запроса — порядок записей будет не определен. Иногда может повезти, как в запросе с рангом по возрастанию зарплаты, а иногда и нет. Полагаться на везение не стоит, поэтому всегда указывайте явно сортировку результатов.
Однозначность сортировки
Еще один частый вопрос — зачем в сортировке результата столбец id:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (order by salary desc)
order by "rank", id;
Почему order by rank, id, а не order by rank? Чтобы знать, как сортировать сотрудников с одинаковым рангом. Без id порядок записей Леонид-Марина и Вероника-Григорий не определен, и СУБД может расположить их в любом порядке. А с id все однозначно: «Леонид, затем Марина» и «Вероника, затем Григорий».
Несколько окон
Еще один частый вопрос (не связанный с сортировкой) — как задать несколько окон в одном запросе.
Просто перечислите их через запятую в разделе window:
select ...
from ...
where ...
window
w1 as (...),
w2 as (...),
w3 as (...)
;
Например, отранжируем сотрудников по зарплате в прямом и обратном порядке:
select
dense_rank() over w1 as r_asc,
dense_rank() over w2 as r_desc,
name, salary
from employees
window
w1 as (order by salary asc),
w2 as (order by salary desc)
order by salary, id;
✎ Задачка: Ранг по имени
Только практика превращает абстрактные знания в навыки. Поэтому я рекомендую не просто читать эту статью, а проходить курс или книгу — в них достаточно упражнений, чтобы уверенно освоить «окошки».
Если вас пока устраивает одна теория — продолжим.
Секции окна
Теперь составим рейтинг сотрудников по размеру заработной платы независимо по каждому департаменту:
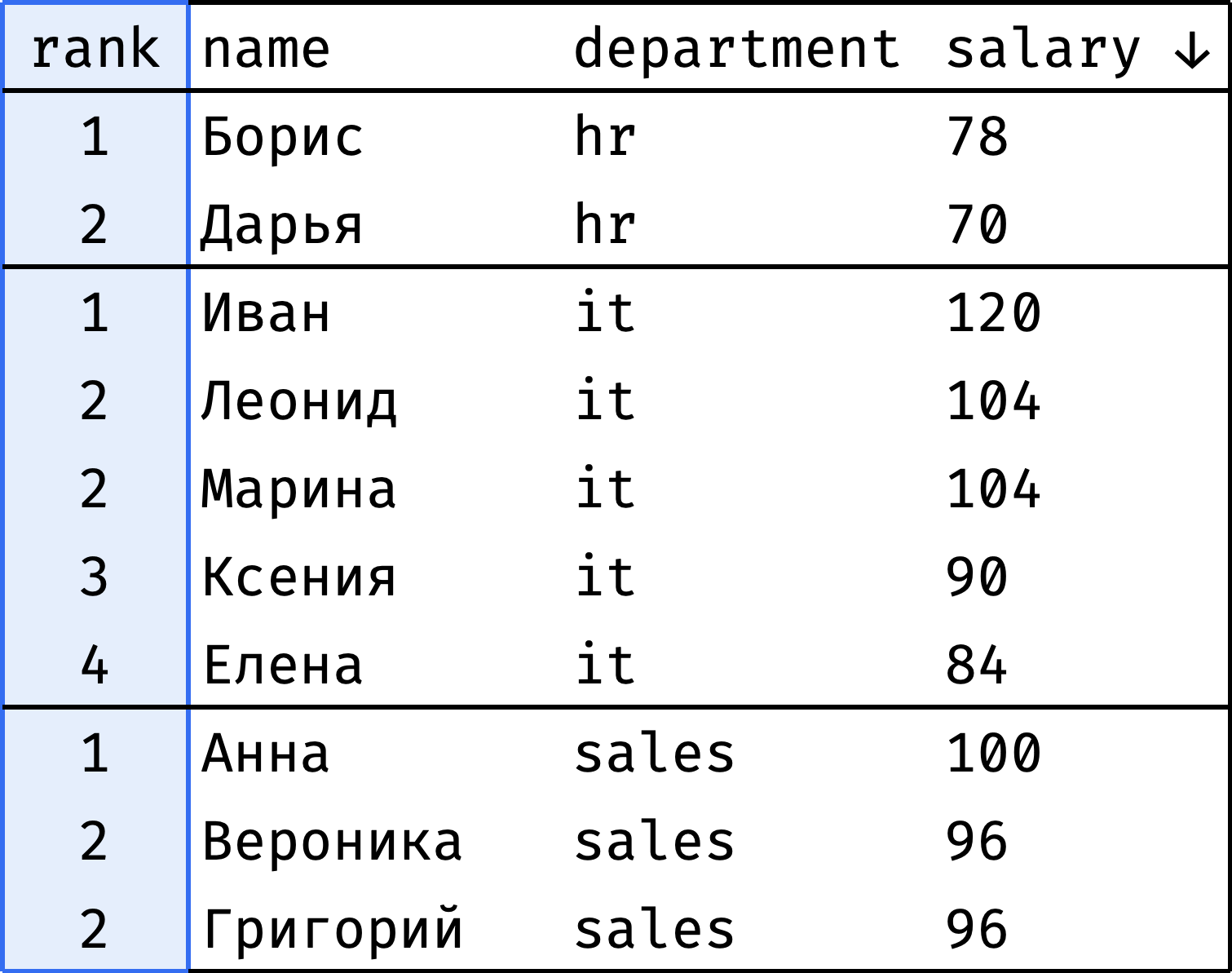
Как перейти от «было» к «стало»?
Сначала отсортируем таблицу по департаментам, а внутри департамента — по убыванию зарплаты:
select
null as "rank",
name, department, salary
from employees
order by department, salary desc, id;
Теперь пройдем от первой строчки до последней и проставим ранг каждой записи. Начнем с 1 и будем увеличивать ранг каждый раз, когда значение salary меньше, чем у предыдущей записи. При переходе от департамента к департаменту будем сбрасывать ранг обратно на 1:
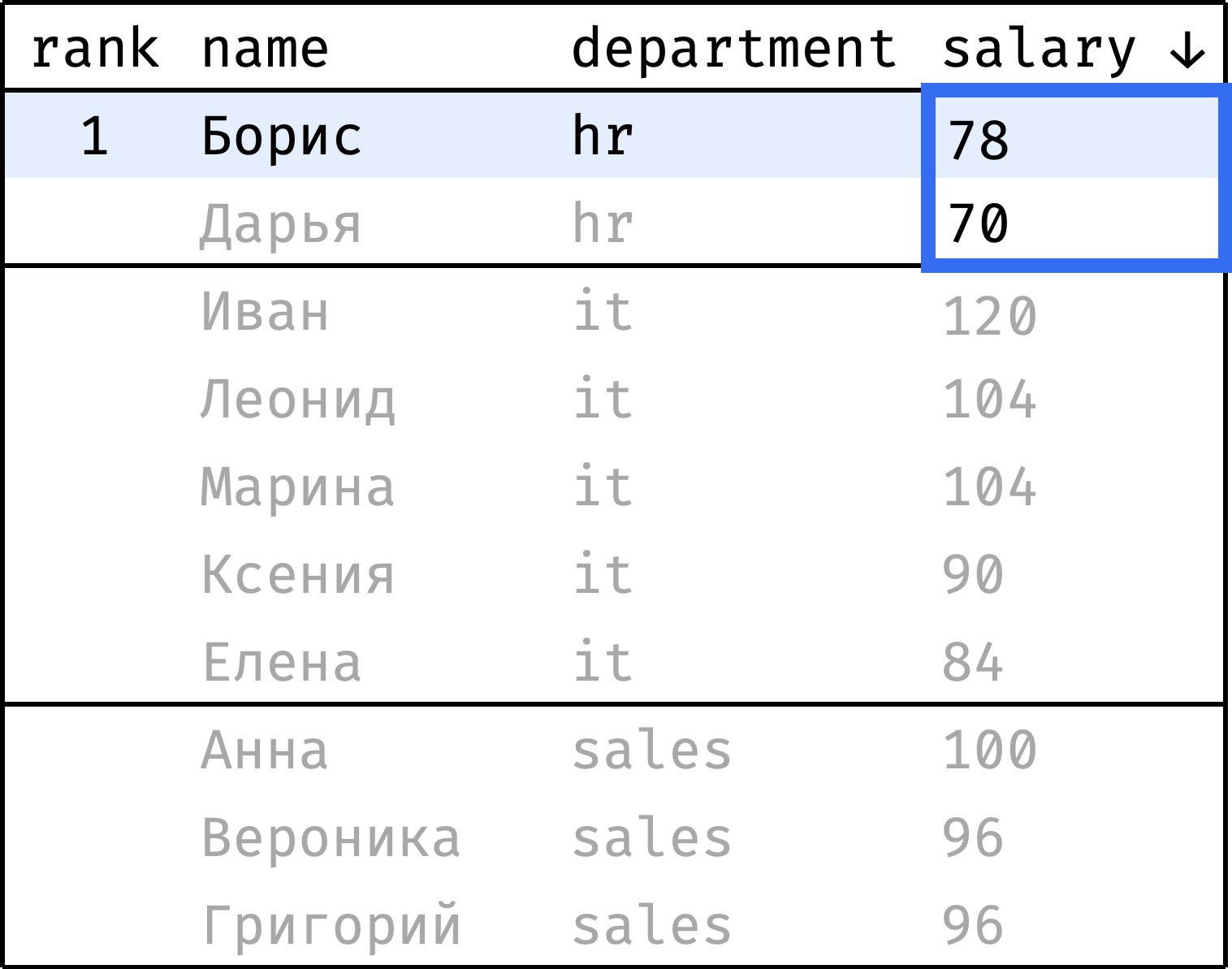
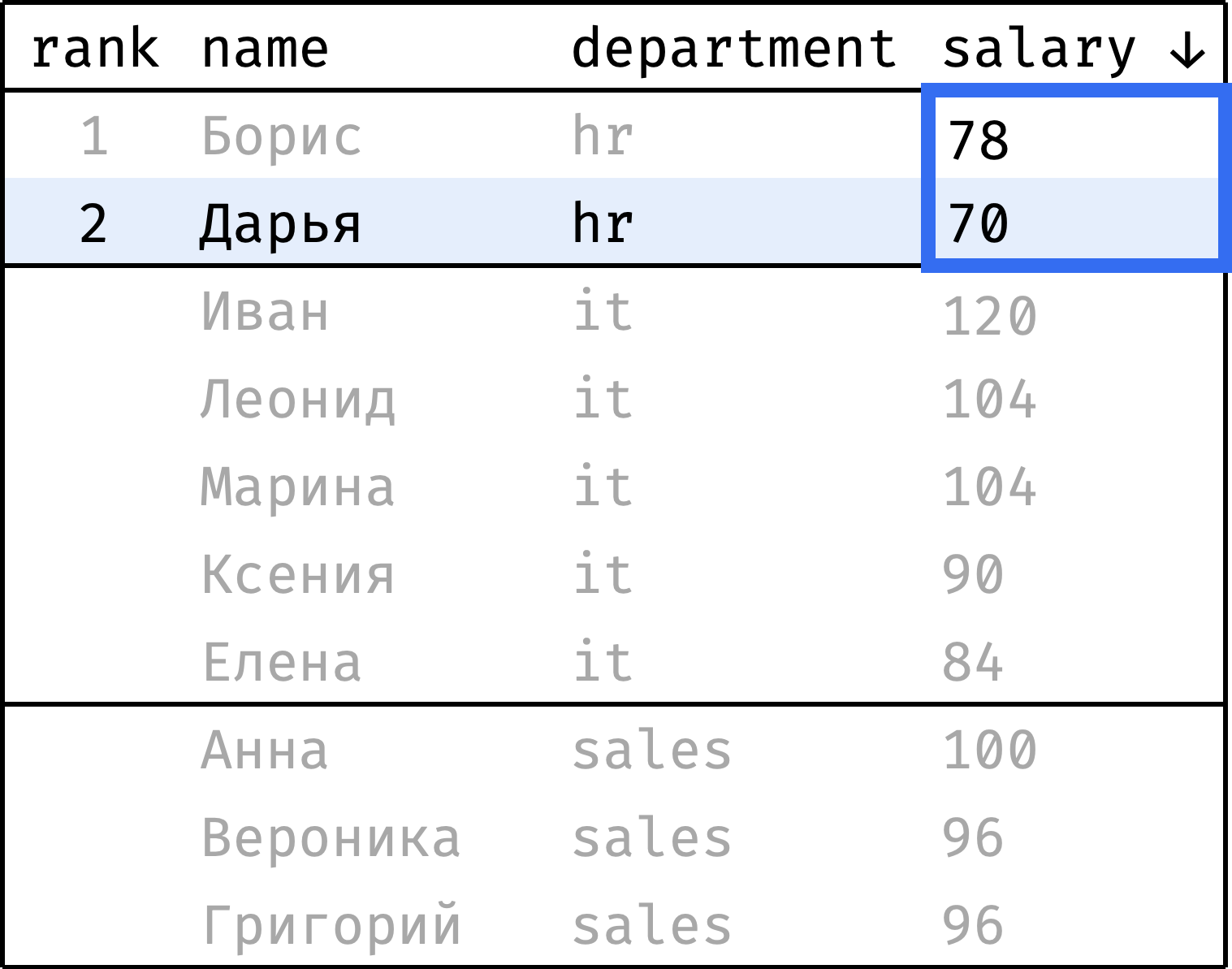
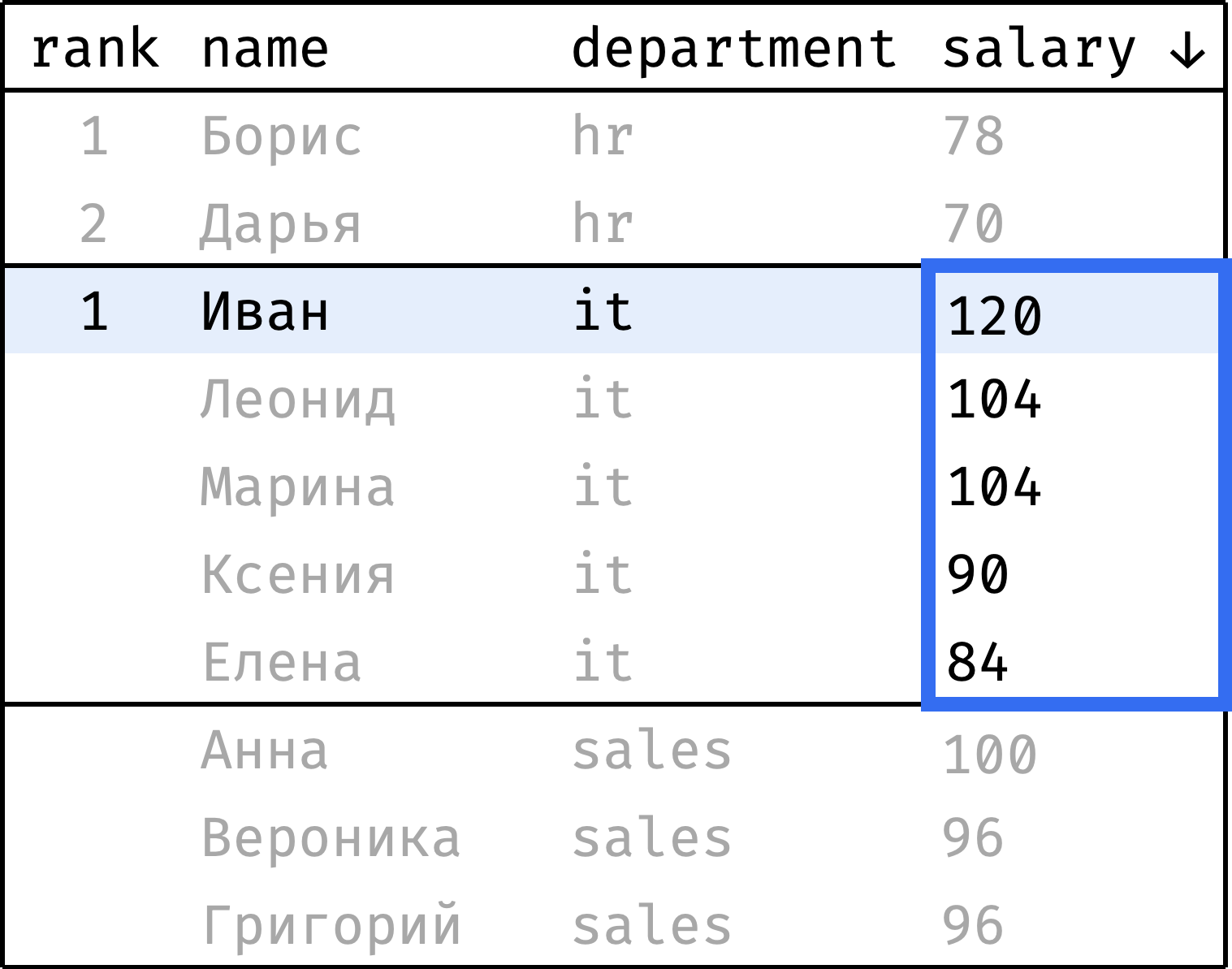
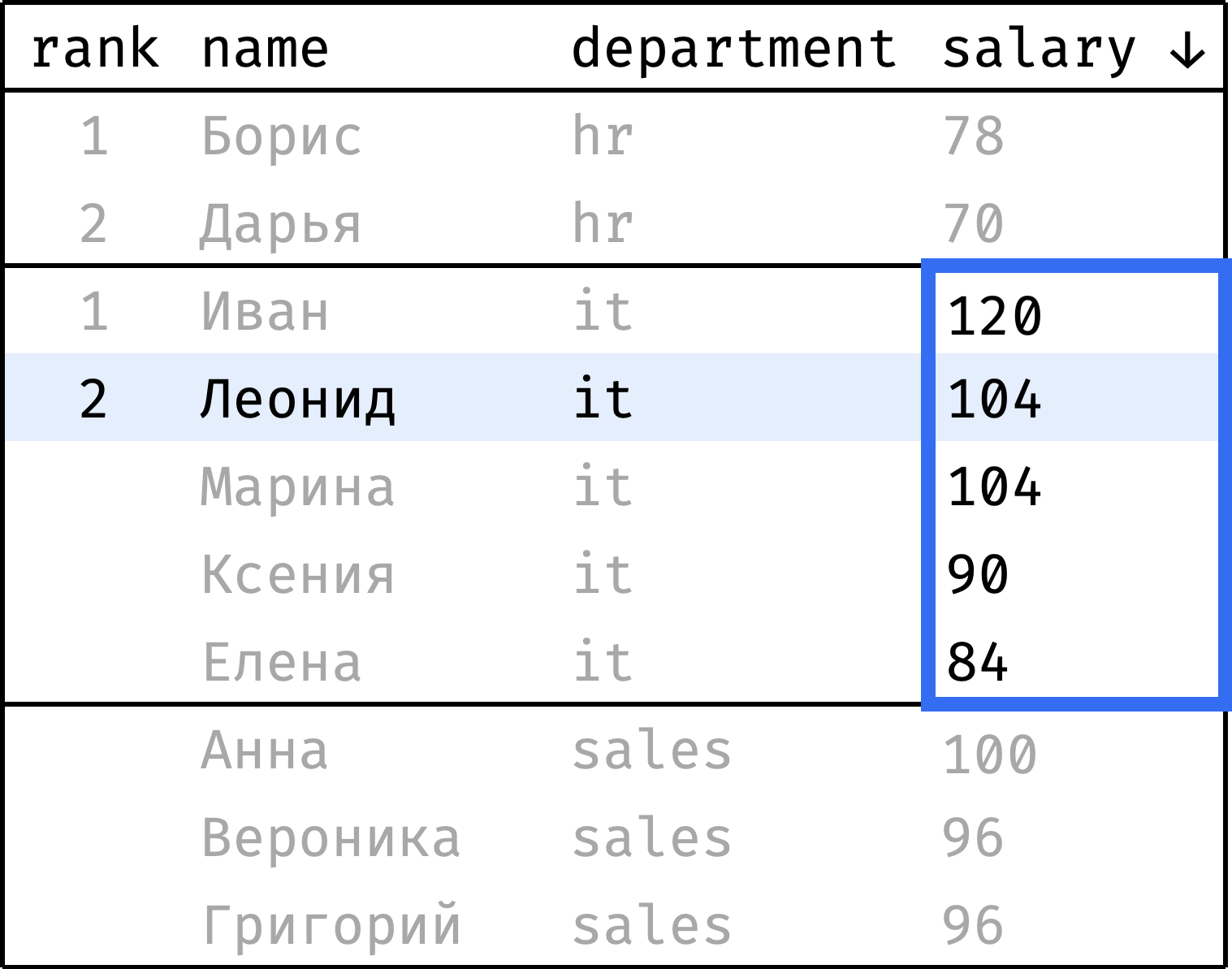
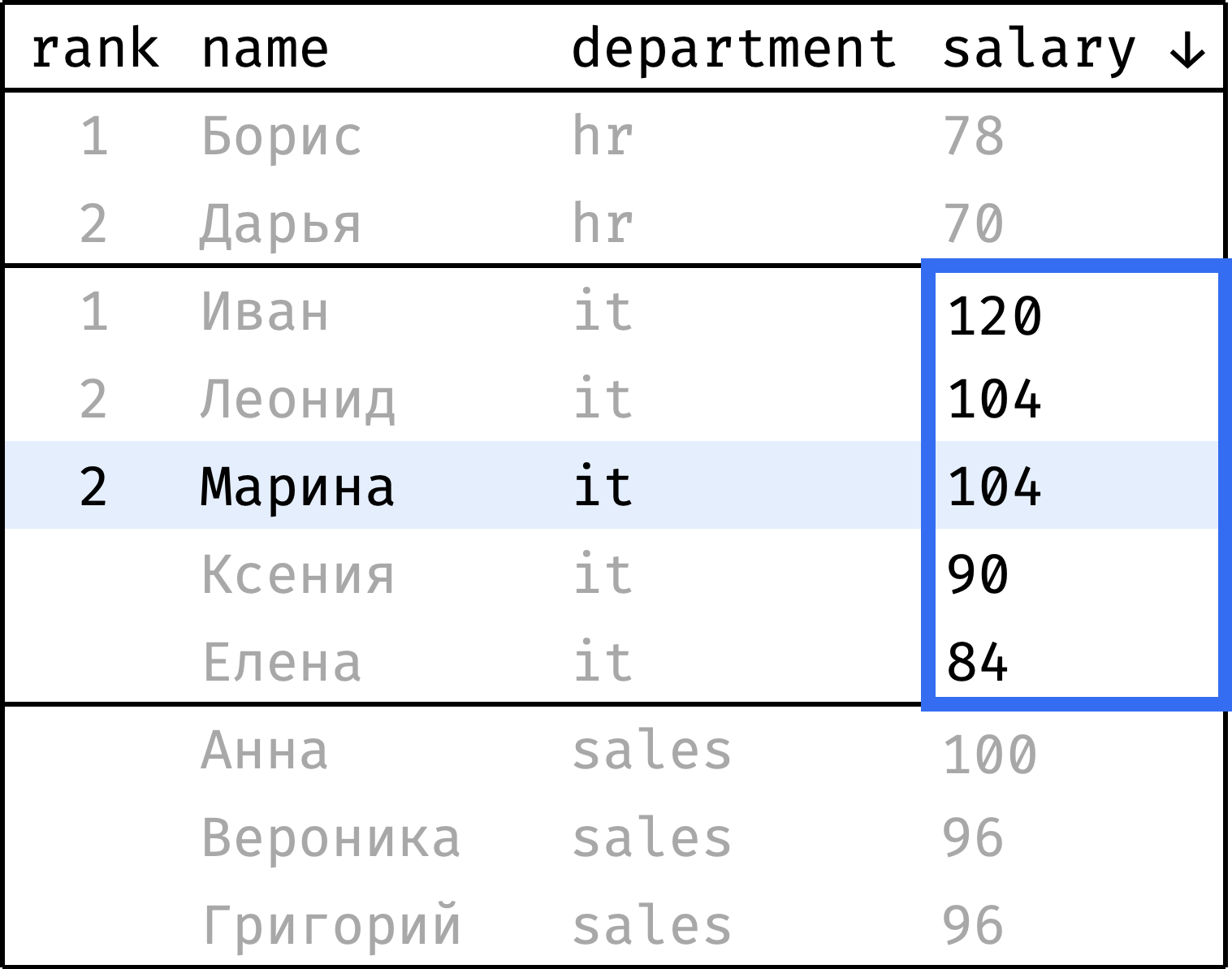
и так далее...
Чтобы проставить ранг, достаточно на каждом шаге смотреть только на значения из столбца salary, выделенные синей рамкой. Это и есть окно в данном случае.
Видно, что окно меняется в зависимости от того, к какому департаменту относится текущая запись. Опишем словами:
- Окно разбито на несколько независимых секций — по одной на департамент.
- Внутри секции записи упорядочены по убыванию зарплаты.
Сформулируем то же самое на SQL:
window w as (
partition by department
order by salary desc
)
partition by departmentуказывает, как следует разбить окно на секции;order by salary descзадает сортировку внутри секции.
Функция расчета ранга остается прежней — dense_rank().
Добавим окно и оконную функцию в исходный запрос:
select
dense_rank() over w as "rank",
name, department, salary
from employees
window w as (
partition by department
order by salary desc
)
order by department, "rank", id;
Вот как движок рассчитывает ранг для каждой записи:

✎ Задачка: Рейтинг зарплат по городам
Только практика превращает абстрактные знания в навыки. Поэтому я рекомендую не просто читать эту статью, а проходить курс или книгу — в них достаточно упражнений, чтобы уверенно освоить «окошки».
Если вас пока устраивает одна теория — продолжим.
Группы
Разобьем сотрудников на три группы в зависимости от размера зарплаты:
- высокооплачиваемые,
- средние,
- низкооплачиваемые.
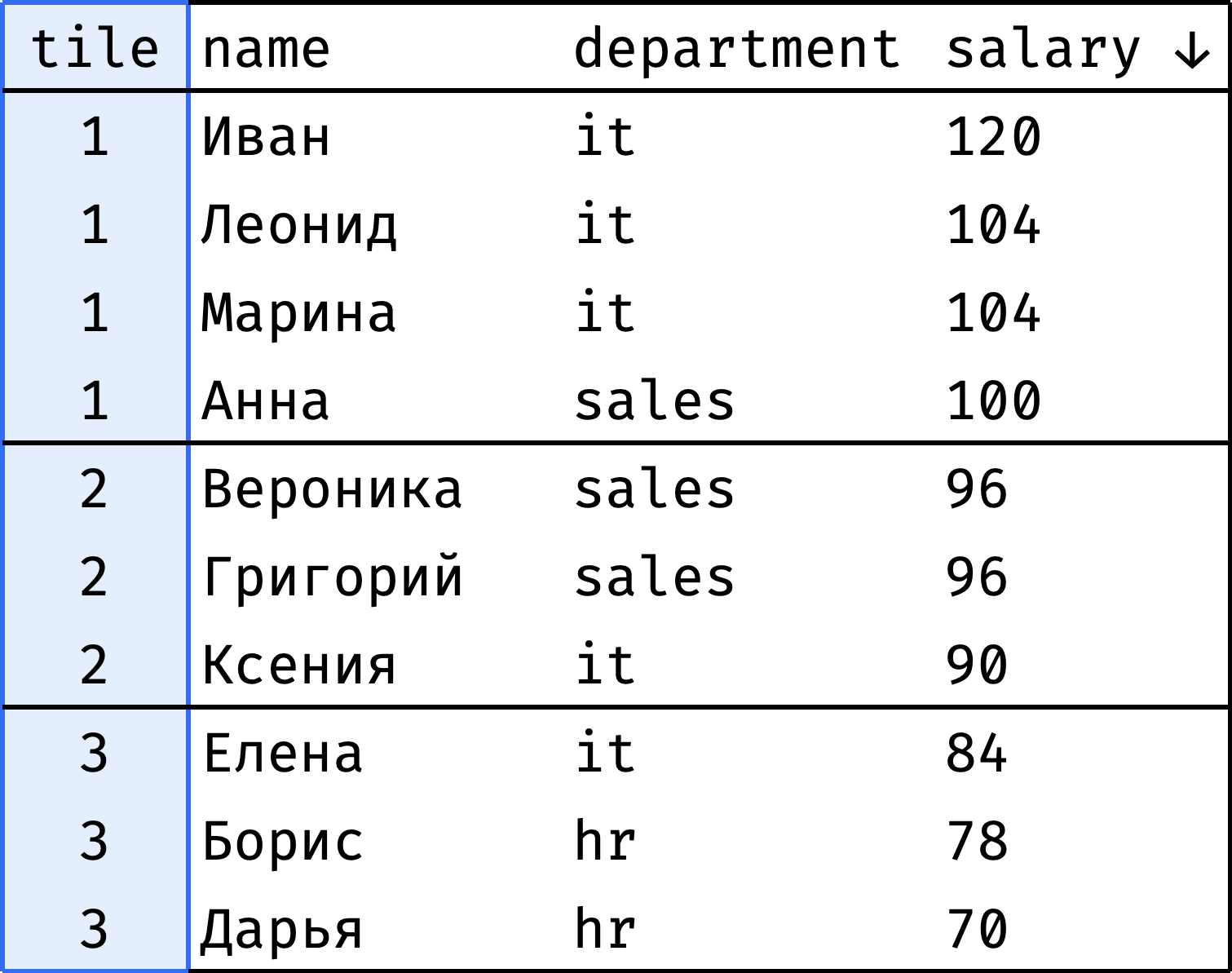
Как перейти от «было» к «стало»?
Сначала отсортируем таблицу по убыванию зарплаты:
select
null as tile,
name, department, salary
from employees
order by salary desc, id;
Всего 10 записей и 3 группы — значит, две группы по 3 записи и одна 4 записи. Например, так:
┌──────┬───────┬────────────┬────────┐
│ tile │ name │ department │ salary │
├──────┼───────┼────────────┼────────┤
│ │ Frank │ it │ 120 │
│ │ Henry │ it │ 104 │
│ │ Irene │ it │ 104 │
│ │ Alice │ sales │ 100 │
├──────┼───────┼────────────┼────────┤
│ │ Cindy │ sales │ 96 │
│ │ Dave │ sales │ 96 │
│ │ Grace │ it │ 90 │
├──────┼───────┼────────────┼────────┤
│ │ Emma │ it │ 84 │
│ │ Bob │ hr │ 78 │
│ │ Diane │ hr │ 70 │
└──────┴───────┴────────────┴────────┘
Чтобы провести границы между группами, придется анализировать все зарплаты, отсортированные по убыванию. Поэтому окно будет таким же, как раньше:
window w as (order by salary desc)
А вот функция потребуется другая — ntile(n), где n — количество групп. В нашем случае n = 3:
select
ntile(3) over w as tile,
name, department, salary
from employees
window w as (order by salary desc)
order by salary desc, id;
ntile(n) разбивает все записи на n групп и возвращает номер группы для каждой записи. Если общее количество записей (10 в нашем случае) не делится на размер группы (3), то первые группы будут крупнее последних.
ntile() всегда старается разбить данные так, чтобы группы были одинакового размера. Поэтому записи с одинаковым значением з/п вполне могут попасть в разные (соседние) группы:
select
ntile(2) over w as tile,
name, department, salary
from employees
window w as (order by salary desc, id)
order by salary desc, tile;
┌──────┬──────────┬────────────┬────────┐
│ tile │ name │ department │ salary │
├──────┼──────────┼────────────┼────────┤
│ 1 │ Иван │ it │ 120 │
│ 1 │ Леонид │ it │ 104 │
│ 1 │ Марина │ it │ 104 │
│ 1 │ Анна │ sales │ 100 │
│ 1 │ Вероника │ sales │ 96 │ <-- (!)
├──────┼──────────┼────────────┼────────┤
│ 2 │ Григорий │ sales │ 96 │ <-- (!)
│ 2 │ Ксения │ it │ 90 │
│ 2 │ Елена │ it │ 84 │
│ 2 │ Борис │ hr │ 78 │
│ 2 │ Дарья │ hr │ 70 │
└──────┴──────────┴────────────┴────────┘
✎ Задачка: Группы по зарплате в городах (+ еще одна)
Только практика превращает абстрактные знания в навыки. Поэтому я рекомендую не просто читать эту статью, а проходить курс или книгу — в них достаточно упражнений, чтобы уверенно освоить «окошки».
Если вас пока устраивает одна теория — продолжим.
Функции ранжирования
Оконные функции ранжирования:
| Функция | Описание |
|---|---|
row_number() | порядковый номер строки number |
dense_rank() | ранг строки rank |
rank() | ранг строки, но с пропусками (см. ниже) |
ntile(n) | разбивает все строки на n групп и возвращает номер группы, в которую попала строка |
dense_rank() и ntile() мы уже разобрали.
row_number() нумерует строки в порядке, указанном в order by. Никаких неожиданностей.
rank() похож на dense_rank(), а разницу проще всего показать на примере.
select
••• over w as "rank",
name, salary
from employees
window w as (order by salary desc)
order by "rank", id;
В одном случае вместо ••• укажем dense_rank(), а в другом — rank():
┌──────┬──────────┬────────┐
│ rank │ name │ salary │
├──────┼──────────┼────────┤
│ 1 │ Иван │ 120 │
│ 2 │ Леонид │ 104 │
│ 2 │ Марина │ 104 │
│ 3 │ Анна │ 100 │ (!)
│ 4 │ Вероника │ 96 │
│ 4 │ Григорий │ 96 │
│ 5 │ Ксения │ 90 │ (!)
│ 6 │ Елена │ 84 │
│ 7 │ Борис │ 78 │
│ 8 │ Дарья │ 70 │
└──────┴──────────┴────────┘┌──────┬──────────┬────────┐
│ rank │ name │ salary │
├──────┼──────────┼────────┤
│ 1 │ Иван │ 120 │
│ 2 │ Леонид │ 104 │
│ 2 │ Марина │ 104 │
│ 4 │ Анна │ 100 │ (!)
│ 5 │ Вероника │ 96 │
│ 5 │ Григорий │ 96 │
│ 7 │ Ксения │ 90 │ (!)
│ 8 │ Елена │ 84 │
│ 9 │ Борис │ 78 │
│ 10 │ Дарья │ 70 │
└──────┴──────────┴────────┘dense_rank() назначает Анне третье место, а rank() — четвертое, потому что второе-третье уже заняты Леонидом и Мариной. Аналогично с Ксенией после Вероники и Григория. Вот и вся разница.
Так держать
Вы узнали, что такое «окно», «оконная функция», и как использовать их для ранжирования данных. На следующем уроке займемся оконными сравнениями!
Записаться на курс или купить книгу (скоро)